# Importación de librerías necesarias para el análisis y modelado
import pandas as pd # Para manipulación de datos
import seaborn as sns # Para visualización estadística
import matplotlib.pyplot as plt # Para control de gráficos
from sklearn.model_selection import train_test_split # Para dividir los datos en entrenamiento y prueba
from sklearn.linear_model import LinearRegression # Algoritmo de regresión lineal
from sklearn.metrics import mean_squared_error, r2_score # Métricas de evaluación
df = pd.read_csv('/content/hoteis.csv')
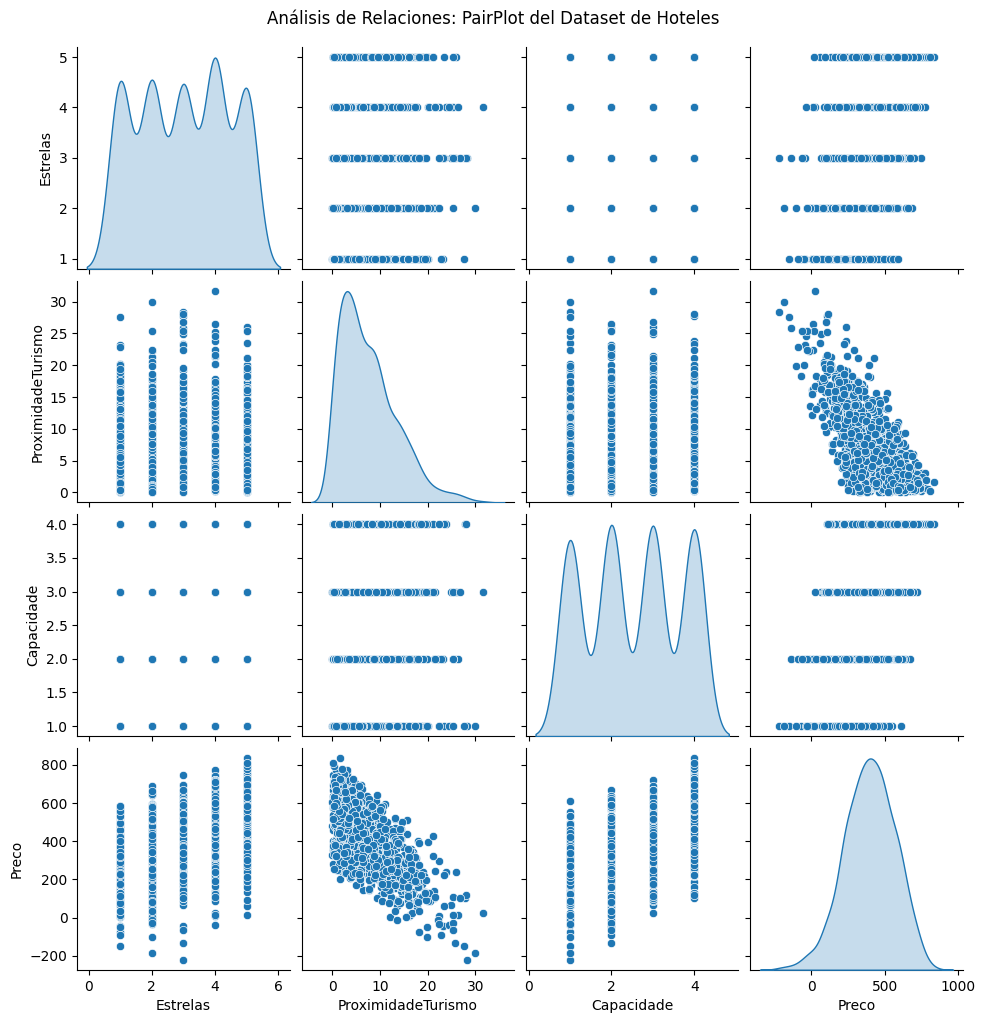
- análisis inicial con el PairPlot de Seaborn;
sns.pairplot(df, diag_kind='kde')
plt.suptitle('Análisis de Relaciones: PairPlot del Dataset de Hoteles', y=1.02)
plt.show()
- construir modelos de regresión lineal;
# Definimos las variables independientes (X) y la variable objetivo (y: Preco)
X = df[['Estrelas', 'ProximidadeTurismo', 'Capacidade']]
y = df['Preco']
# Dividimos los datos: 80% para entrenamiento y 20% para pruebas
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Regresión Lineal Simple
model_simple = LinearRegression() # Inicializamos el modelo
model_simple.fit(X_train[['ProximidadeTurismo']], y_train) # Entrenamos con una sola variable
y_pred_simple = model_simple.predict(X_test[['ProximidadeTurismo']]) # Generamos predicciones
# Regresión Lineal Múltiple
model_multiple = LinearRegression() # Inicializamos el segundo modelo
model_multiple.fit(X_train, y_train) # Entrenamos con todas las características
y_pred_multiple = model_multiple.predict(X_test) # Generamos predicciones
- realizar la comparación de estos modelos.
def mostrar_metricas(nombre, y_true, y_pred):
mse = mean_squared_error(y_true, y_pred)
r2 = r2_score(y_true, y_pred)
print(f"Resultados para {nombre}:")
print(f" - Error Cuadrático Medio (MSE): {mse:.2f}")
print(f" - Coeficiente de Determinación (R2): {r2:.4f}")
print("-" * 30)
# resultados comparativos
print("COMPARACIÓN DE MODELOS\n")
mostrar_metricas("Modelo Simple (Distancia)", y_test, y_pred_simple)
mostrar_metricas("Modelo Múltiple (Todas las variables)", y_test, y_pred_multiple)
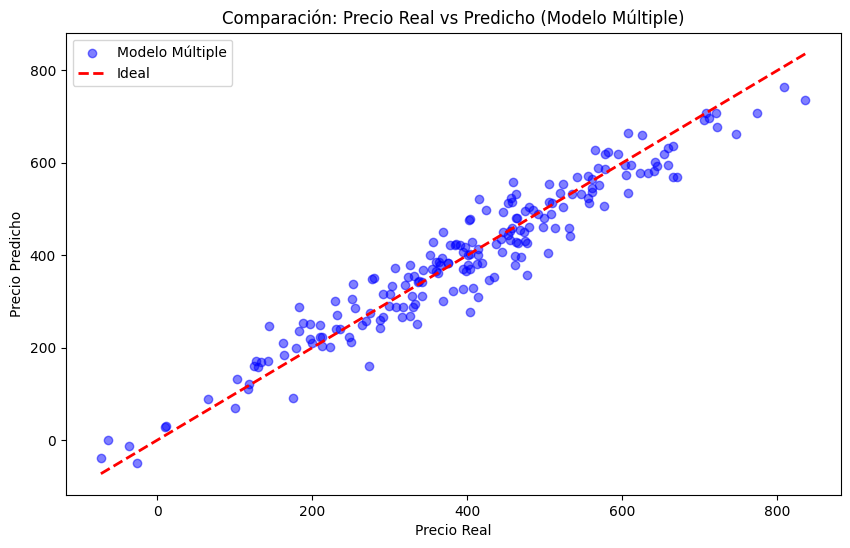
# Visualización
plt.figure(figsize=(10, 6))
plt.scatter(y_test, y_pred_multiple, alpha=0.5, label='Modelo Múltiple', color='blue')
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--', lw=2, label='Ideal')
plt.xlabel('Precio Real')
plt.ylabel('Precio Predicho')
plt.title('Comparación: Precio Real vs Predicho (Modelo Múltiple)')
plt.legend()
plt.show()