Primera etapa: Verifica la multicolinealidad utilizando el concepto de VIF. Si hay indicios de multicolinealidad entre las variables, intenta pensar en qué medidas se pueden tomar. Para ello, deberás construir un modelo de regresión lineal asumiendo que la columna PE es la variable y.
import pandas as pd
import numpy as np
import statsmodels.api as sm
from statsmodels.stats.outliers_influence import variance_inflation_factor
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv('/content/usina.csv')
X = df.drop('PE', axis=1)
y = df['PE']
X_const = sm.add_constant(X)
vif_data = pd.DataFrame()
vif_data["Variable"] = X_const.columns
vif_data["VIF"] = [variance_inflation_factor(X_const.values, i) for i in range(X_const.shape[1])]
print("Análisis de Multicolinealidad (VIF)")
print(vif_data)
print("\nNota: VIF > 5 indica presencia de multicolinealidad moderada.")
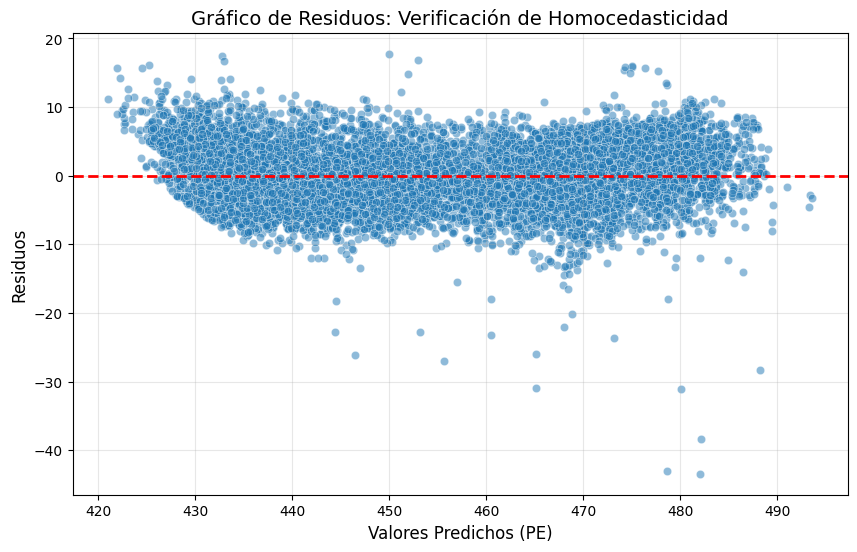
Segunda etapa: Realiza un análisis de residuos e identifica si hay o no heterocedasticidad en los datos.
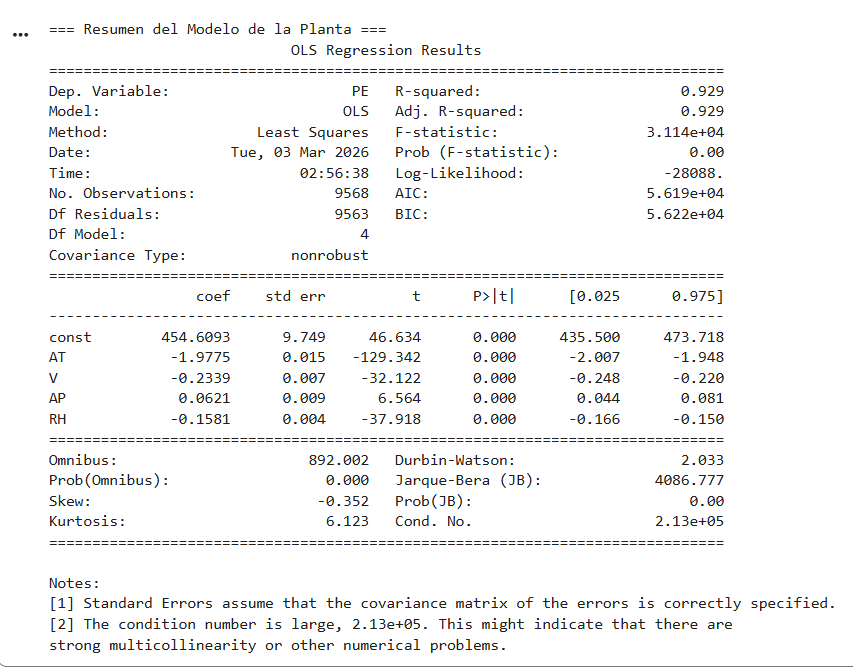
modelo_usina = sm.OLS(y, X_const).fit()
predicciones = modelo_usina.fittedvalues
residuos = modelo_usina.resid
plt.figure(figsize=(10, 6))
sns.scatterplot(x=predicciones, y=residuos, alpha=0.5)
plt.axhline(y=0, color='red', linestyle='--', linewidth=2)
plt.title('Gráfico de Residuos: Verificación de Homocedasticidad', fontsize=14)
plt.xlabel('Valores Predichos (PE)', fontsize=12)
plt.ylabel('Residuos', fontsize=12)
plt.grid(True, alpha=0.3)
plt.show()
print("\nResumen del Modelo de la Planta")
print(modelo_usina.summary())