import re
def censurar_texto():
print("==================================================")
print(" CENSURADOR DE PALABRAS EN TEXTO ")
print("==================================================\n")
# 1. Solicitar el texto al usuario
texto_original = input("Ingrese el texto a procesar:\n> ")
if not texto_original.strip():
print("El texto ingresado está vacío. Saliendo del programa.")
return
# 2. Solicitar las palabras prohibidas
entrada_prohibidas = input("\nIngrese las palabras prohibidas separadas por comas:\n> ")
# Procesar la lista de palabras prohibidas:
# - Dividimos por comas
# - Eliminamos espacios en blanco al inicio/final de cada palabra
# - Filtramos posibles entradas vacías (por ejemplo, si el usuario escribe doble coma)
palabras_prohibidas = [
palabra.strip()
for palabra in entrada_prohibidas.split(",")
if palabra.strip()
]
if not palabras_prohibidas:
print("\nNo se ingresaron palabras prohibidas válidas.")
print("Texto original sin cambios:")
print(texto_original)
return
# 3. Crear el patrón de expresión regular
# Usamos re.escape para evitar que caracteres especiales en las palabras rompan la regex.
# Empleamos límites de palabra '\b' para que no censure partes de otras palabras de forma accidental
# (por ejemplo, evitar que "carne" censure parcialmente "carnero").
palabras_escapadas = [re.escape(p) for p in palabras_prohibidas]
patron_regex = r'\b(' + '|'.join(palabras_escapadas) + r')\b'
# Función auxiliar para realizar el reemplazo manteniendo la longitud de la palabra encontrada
def reemplazar(match):
palabra_detectada = match.group(0)
return '*' * len(palabra_detectada)
# 4. Reemplazar e ignorar mayúsculas/minúsculas usando re.IGNORECASE
# re.subn devuelve una tupla: (texto_modificado, cantidad_de_reemplazos)
texto_censurado, total_censuradas = re.subn(
patron_regex,
reemplazar,
texto_original,
flags=re.IGNORECASE
)
# 5. Mostrar los resultados por pantalla
print("\n==================================================")
print(" RESULTADOS ")
print("==================================================")
print(f"Texto original:\n{texto_original}\n")
print(f"Texto censurado:\n{texto_censurado}\n")
print(f"Cantidad total de palabras censuradas: {total_censuradas}")
print("==================================================")
if __name__ == "__main__":
censurar_texto()
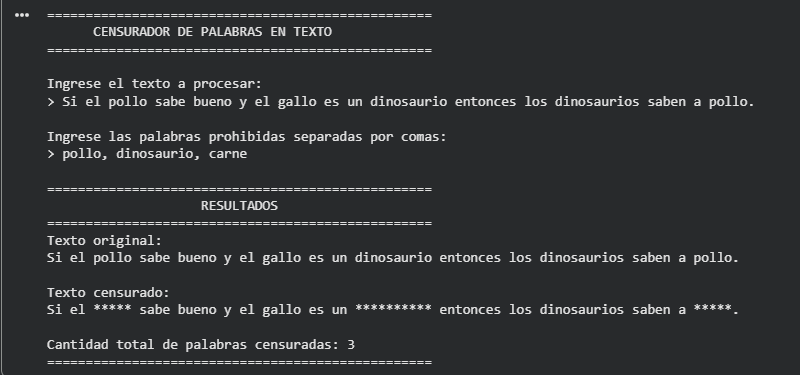
Como vemos si deja bloquear el texto tal y como se requiere.