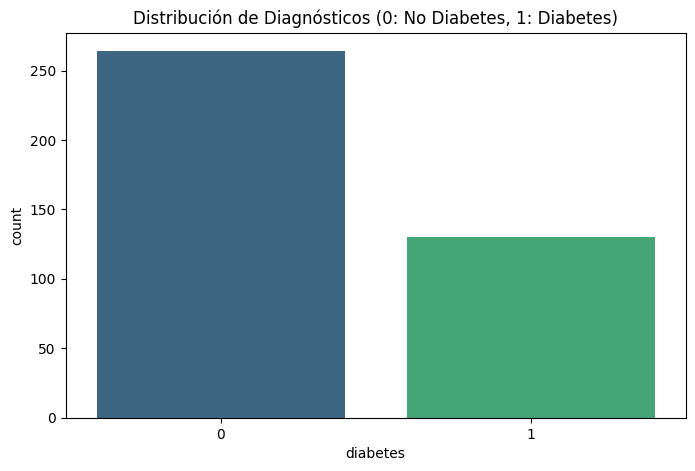
- Actividad 1: Identificación del Desbalanceo En esta etapa verificamos la proporción de la variable objetivo. Un desbalanceo ignorado puede hacer que el modelo sea un "adicto a la mayoría", ignorando los casos positivos de diabetes por simple probabilidad.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_csv('/content/diabetes.csv')
# 1.1 Análisis porcentual
proporcion = df['diabetes'].value_counts(normalize=True) * 100
print("Proporción de la variable objetivo:")
print(proporcion)
# 1.2 Análisis visual
plt.figure(figsize=(8, 5))
sns.countplot(data=df, x='diabetes', palette='viridis')
plt.title('Distribución de Diagnósticos (0: No Diabetes, 1: Diabetes)')
plt.show()
# Los datos muestran aproximadamente un 67% de casos negativos y un 33% positivos.
# Existe un desbalanceo moderado (2:1). Aunque no es extremo, justifica el uso de técnicas de balanceo.

- Actividad 2 y 3: Implementación de Pipelines (Oversampling vs Undersampling) Utilizaremos Pipeline para asegurar que el balanceo se aplique solo en el entrenamiento de cada pliegue de la validación cruzada, evitando la "fuga de datos".
from sklearn.model_selection import train_test_split, StratifiedKFold, cross_val_score
from sklearn.ensemble import RandomForestClassifier
from imblearn.over_sampling import SMOTE
from imblearn.under_sampling import NearMiss
from imblearn.pipeline import Pipeline
import numpy as np
X = df.drop('diabetes', axis=1)
y = df['diabetes']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)
# Modelo base para la comparación
model = RandomForestClassifier(random_state=42)
skf = StratifiedKFold(n_splits=10, shuffle=True, random_state=42)
# SMOTE (Oversampling)
pipeline_smote = Pipeline([
('smote', SMOTE(random_state=42)),
('model', model)
])
score_smote = cross_val_score(pipeline_smote, X_train, y_train, cv=skf, scoring='f1').mean()
print(f"Media F1-Score con SMOTE: {score_smote:.4f}")
# NearMiss v3
pipeline_nm = Pipeline([
('nearmiss', NearMiss(version=3)),
('model', model)
])
score_nm = cross_val_score(pipeline_nm, X_train, y_train, cv=skf, scoring='f1').mean()
print(f"Media F1-Score con NearMiss v3: {score_nm:.4f}")

- Actividad 4: Selección y Evaluación Final En este punto, el código elige automáticamente la mejor estrategia basada en el desempeño previo y realiza la prueba definitiva.
from sklearn.metrics import classification_report, confusion_matrix
if score_smote >= score_nm:
mejor_estrategia = "SMOTE"
mejor_pipeline = pipeline_smote
else:
mejor_estrategia = "NearMiss v3"
mejor_pipeline = pipeline_nm
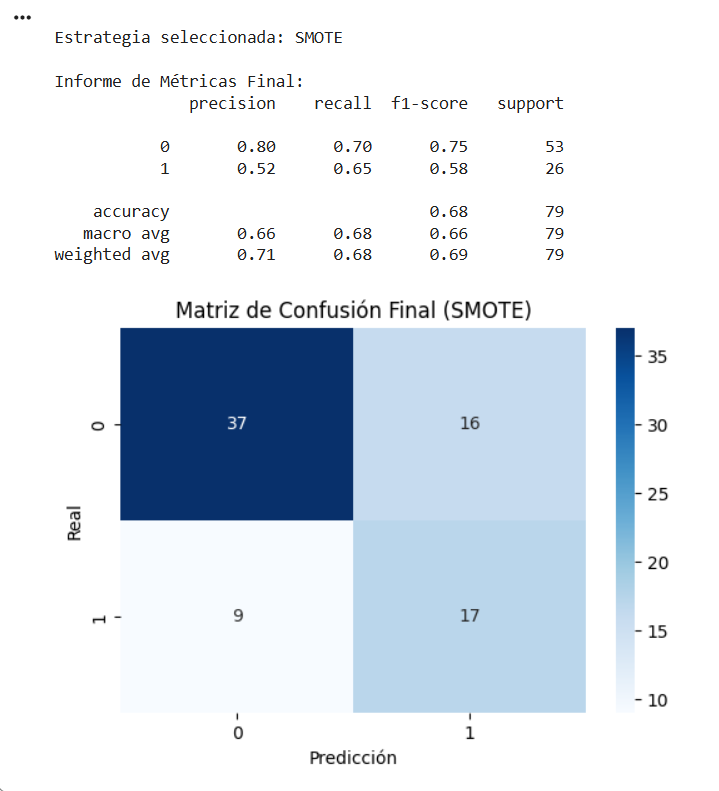
print(f"\nEstrategia seleccionada: {mejor_estrategia}")
# Entrenamiento con todos los datos
mejor_pipeline.fit(X_train, y_train)
# Evaluación final con el conjunto de prueba
y_pred = mejor_pipeline.predict(X_test)
print("\nInforme de Métricas Final:")
print(classification_report(y_test, y_pred))
# Matriz de Confusión
plt.figure(figsize=(6, 4))
sns.heatmap(confusion_matrix(y_test, y_pred), annot=True, fmt='d', cmap='Blues')
plt.title(f'Matriz de Confusión Final ({mejor_estrategia})')
plt.xlabel('Predicción')
plt.ylabel('Real')
plt.show()