import pandas as pd
import matplotlib.pyplot as plt
from google.colab import files
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import (
accuracy_score, precision_score, recall_score, f1_score,
RocCurveDisplay, PrecisionRecallDisplay, classification_report
)
df = pd.read_csv('/content/diabetes.csv')
X = df.drop(columns=['diabetes'])
y = df['diabetes']
# División de datos: 5% Prueba, y del 95% restante, 25% Validación.
X_temp, X_test, y_temp, y_test = train_test_split(
X, y, test_size=0.05, stratify=y, random_state=42
)
X_train, X_val, y_train, y_val = train_test_split(
X_temp, y_temp, test_size=0.25, stratify=y_temp, random_state=42
)
# Definición y entrenamiento de modelos
dt_model = DecisionTreeClassifier(max_depth=3, random_state=42).fit(X_train, y_train)
rf_model = RandomForestClassifier(max_depth=2, random_state=42).fit(X_train, y_train)
# Obtención de predicciones y probabilidades
y_pred_dt = dt_model.predict(X_test)
y_prob_dt = dt_model.predict_proba(X_test)[:, 1]
y_pred_rf = rf_model.predict(X_test)
y_prob_rf = rf_model.predict_proba(X_test)[:, 1]
# EXTRACCIÓN DE MÉTRICAS NUMÉRICAS
def mostrar_metricas(y_true, y_pred, nombre_modelo):
print(f"\n>>> Métricas: {nombre_modelo}")
print(f"- Exactitud (Accuracy): {accuracy_score(y_true, y_pred):.4f}")
print(f"- Precisión (Precision): {precision_score(y_true, y_pred):.4f}")
print(f"- Recuperación (Recall): {recall_score(y_true, y_pred):.4f}")
print(f"- F1-Score: {f1_score(y_true, y_pred):.4f}")
mostrar_metricas(y_test, y_pred_dt, "Decision Tree")
mostrar_metricas(y_test, y_pred_rf, "Random Forest")
# ANÁLISIS GRÁFICO
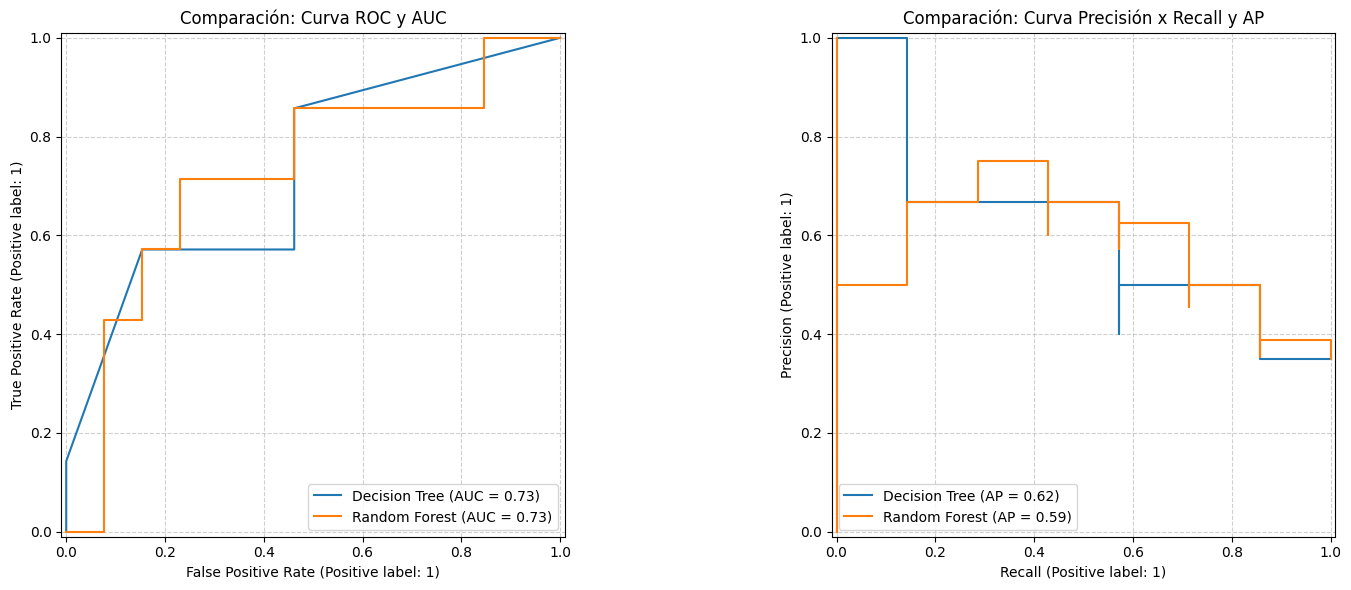
fig, (ax_roc, ax_pr) = plt.subplots(1, 2, figsize=(16, 6))
# Curva ROC y AUC
RocCurveDisplay.from_predictions(y_test, y_prob_dt, ax=ax_roc, name='Decision Tree')
RocCurveDisplay.from_predictions(y_test, y_prob_rf, ax=ax_roc, name='Random Forest')
ax_roc.set_title('Comparación: Curva ROC y AUC')
ax_roc.grid(True, linestyle='--', alpha=0.6)
# Curva Precisión x Recall y AP
PrecisionRecallDisplay.from_predictions(y_test, y_prob_dt, ax=ax_pr, name='Decision Tree')
PrecisionRecallDisplay.from_predictions(y_test, y_prob_rf, ax=ax_pr, name='Random Forest')
ax_pr.set_title('Comparación: Curva Precisión x Recall y AP')
ax_pr.grid(True, linestyle='--', alpha=0.6)
plt.tight_layout()
plt.show()
# INFORME DE CLASIFICACIÓN
print("\n" + "="*60)
print("INFORME DE CLASIFICACIÓN DETALLADO")
print("="*60)
print("\n[DECISION TREE]")
print(classification_report(y_test, y_pred_dt, target_names=['No Diabetes', 'Diabetes']))
print("\n[RANDOM FOREST]")
print(classification_report(y_test, y_pred_rf, target_names=['No Diabetes', 'Diabetes']))