Para evitar que el modelo se ajuste demasiado a los datos de entrenamiento, debemos prestar atención a parámetros como n_estimators (número de árboles) y max_depth (profundidad máxima).
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, ConfusionMatrixDisplay
# Instanciamos el modelo con parámetros para controlar el sobreajuste
# n_estimators=100 es el estándar; max_depth evita árboles infinitos
rf_model = RandomForestClassifier(n_estimators=100, max_depth=10, random_state=42, class_weight='balanced')
# Entrenamos con el conjunto de entrenamiento
rf_model.fit(X_train, y_train)
# Realizamos las predicciones
y_pred_rf = rf_model.predict(X_test)

Visualización de la Matriz de Confusión
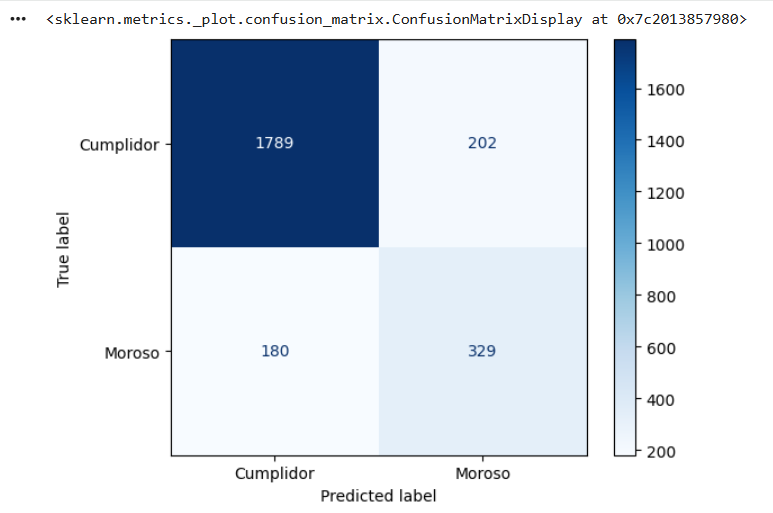
Es fundamental visualizar cuántos de esos 939 errores (Falsos Negativos) que vimos en el ejemplo anterior logra rescatar el Random Forest.
# matriz para Random Forest
cm_rf = confusion_matrix(y_test, y_pred_rf)
disp = ConfusionMatrixDisplay(confusion_matrix=cm_rf, display_labels=['Cumplidor', 'Moroso'])
disp.plot(cmap='Blues')