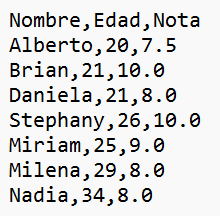
1. Verifica si la base de datos contiene datos nulos y, en caso de tenerlos, realiza el tratamiento de estos datos nulos de la manera que consideres más coherente con la situación.
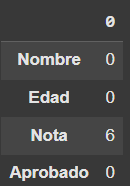
# Muestra el conteo de nulos
df_alumnos.isnull().sum()
# Reemplazo los nulos por nota: 1
df_alumnos = df_alumnos.fillna(1)
df_alumnos
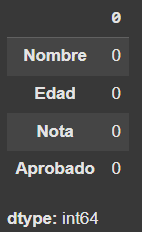
# Compruebo que no hayan nulos
df_alumnos.isnull().sum()
2. Los estudiantes "Alicia" y "Carlos" ya no forman parte del grupo. Por lo tanto, elimínalos de la base de datos.
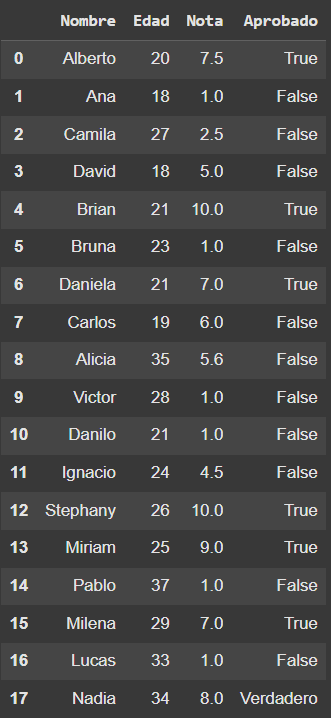
# Mi DataFrame de alumnos
df_alumnos
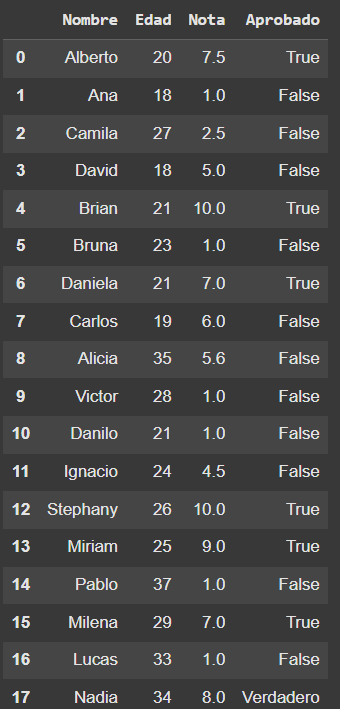
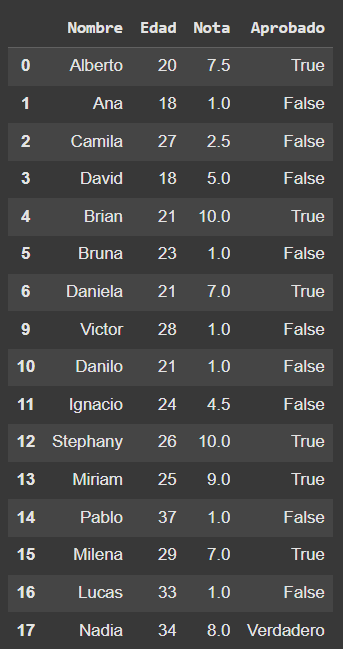
# Remover alumnos Carlos[7] y Alicia[8]
df_alumnos.drop([7,8],axis=0,inplace=True)
# Mostramos el DataFrame alumnos con los cambios realizados
df_alumnos
3. Aplica un filtro que seleccione solo a los estudiantes que fueron aprobados.
# Se reemplaza 'Verdadero' por 'True'
df_alumnos['Aprobado'] = df_alumnos['Aprobado'].replace('Verdadero','True')
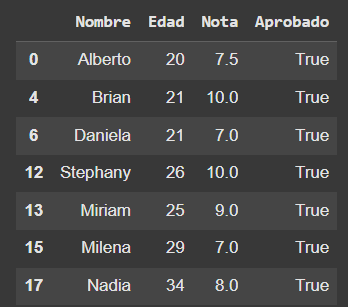
# Filtro (o máscara) de alumnos aprobados
filtro_alumnos_aprobados = df_alumnos['Aprobado'] == 'True'
# Nuevo DataFrame solamente con los alumnos aprobados
df_alumnos_aprobados = df_alumnos[filtro_alumnos_aprobados].copy()
df_alumnos_aprobados
# Verificamos que solo tenemos alumnos aprobados como datos únicos
df_alumnos_aprobados.Aprobado.unique()

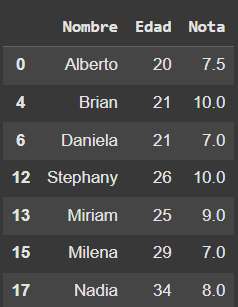
# En este caso, eliminaremos la columna 'Aprobado', ya que no la necesitaremos
df_alumnos_aprobados.drop('Aprobado',axis=1,inplace=True)
df_alumnos_aprobados
4. Guarda el DataFrame que contiene solo a los estudiantes aprobados en un archivo CSV llamado "alumnos_aprobados.csv".
# Guarda el DataFrame de alumnos en GoogleDrive
df_alumnos_aprobados.to_csv('/content/drive/MyDrive/Pandas/ejercicio_alumnos.csv',index=False)
# Lectura del archivo
pd.read_csv('/content/drive/MyDrive/Pandas/ejercicio_alumnos.csv')
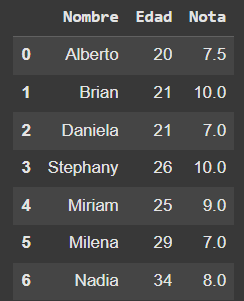
Extra: Al revisar las calificaciones de los estudiantes aprobados, notamos que algunas calificaciones eran incorrectas. Las estudiantes que obtuvieron una calificación de 7.0, en realidad tenían un punto extra que no se contabilizó. Por lo tanto, reemplaza las calificaciones de 7.0 en la base de datos por 8.0. Consejo: busca el método replace.
# Reemplaza las notas 7 por notas 8
df_alumnos_aprobados = df_alumnos_aprobados.replace(7,8)
df_alumnos_aprobados
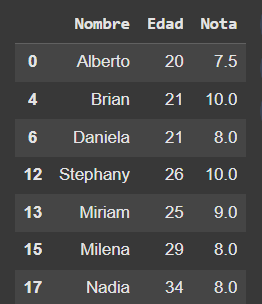
# Guardamos y leemos nuestro archivo
df_alumnos_aprobados.to_csv('/content/drive/MyDrive/Pandas/ejercicio_alumnos.csv',index=False)
pd.read_csv('/content/drive/MyDrive/Pandas/ejercicio_alumnos.csv')
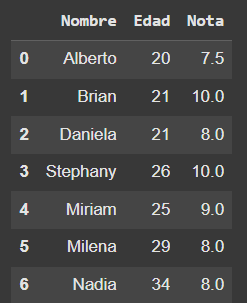
Archivo resultante