import pandas as pd
url='https://gist.githubusercontent.com/ahcamachod/807a2c1cf6c19108b2b701ea1791ab45/raw/fb84f8b2d8917a89de26679eccdbc8f9c1d2e933/alumnos.csv'
# leer los datos
pd.read_csv(url)
datos = pd.read_csv(url)
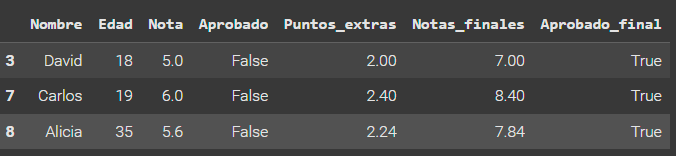
1- Los estudiantes participaron en una actividad extracurricular y ganaron puntos extras. Estos puntos extras corresponden al 40% de su nota actual. Por lo tanto, crea una columna llamada "Puntos_extras" que contenga los puntos extras de cada estudiante, es decir, el 40% de su nota actual.
datos['Puntos_extras'] = datos['Nota'].apply(lambda x: x*0.4)
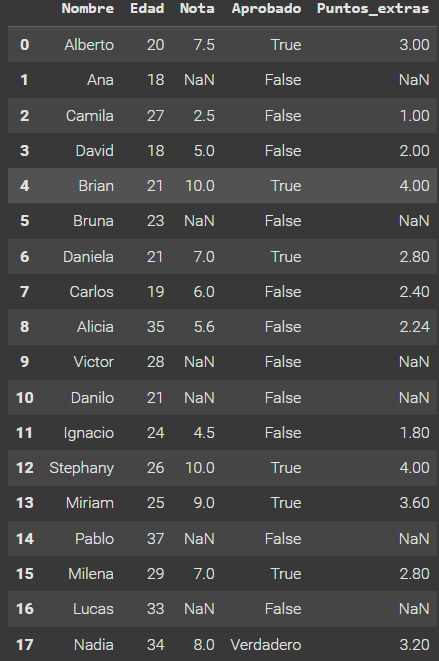
2- Crea otra columna llamada "Notas_finales" que contenga las notas de cada estudiante sumadas con los puntos extras.
# La columna "Notas_finales" será la suma de las columnas "Nota" y "Puntos_extras":
datos['Notas_finales'] = datos['Nota'] + datos['Puntos_extras']
datos
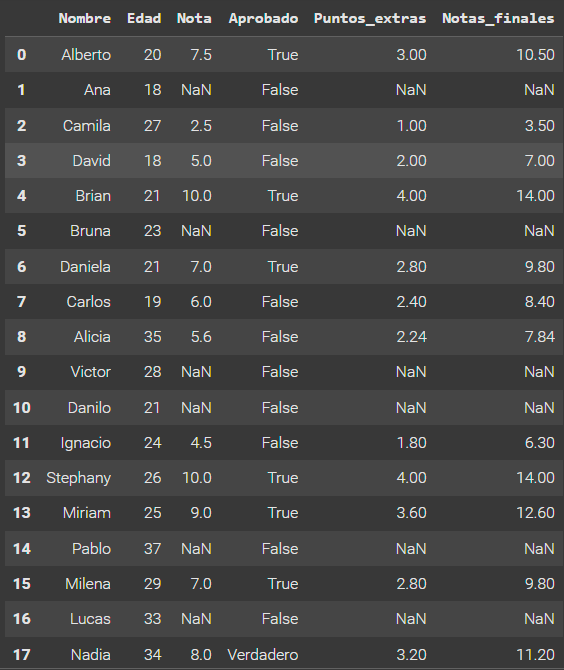
3- Dado que hubo una puntuación extra, algunos estudiantes que no habían sido aprobados antes pueden haber sido aprobados ahora. En función de esto, crea una columna llamada "Aprobado_final" con los siguientes valores: True: si el estudiante está aprobado (la nota final debe ser mayor o igual a 7.0). False: si el estudiante está reprobado (la nota final debe ser menor que 7.0).
datos['Aprobado_final'] = datos['Notas_finales'].apply(lambda x: True if x >= 7.0 else False)
datos
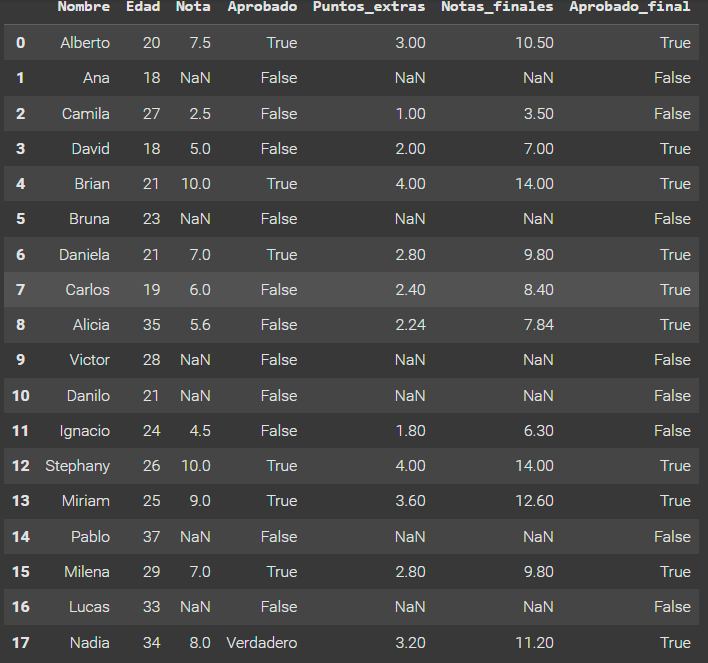
4- Realiza una selección y verifica qué estudiantes no habían sido aprobados anteriormente, pero ahora fueron aprobados después de sumar los puntos extras.
# Verificar los tipos de datos que contienen las columnas del df
datos.info()
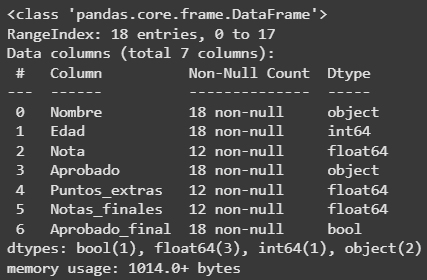
# El tipo de datos de Aprobado es object y Aprobado final es boolean
seleccionados = datos.query('Aprobado == "False" & Aprobado_final == True')
seleccionados
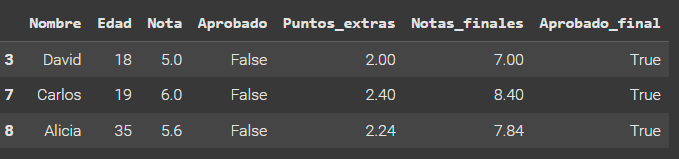
De la forma manual que se propone da el mismo resultado
# El tipo de datos de Aprobado es object y Aprobado final es boolean
seleccion = (datos['Aprobado'] == "False") & (datos['Aprobado_final'] == True)
datos[seleccion]