import pandas as pd
url = 'https://gist.githubusercontent.com/ahcamachod/807a2c1cf6c19108b2b701ea1791ab45/raw/fb84f8b2d8917a89de26679eccdbc8f9c1d2e933/alumnos.csv'
pd.read_csv(url)
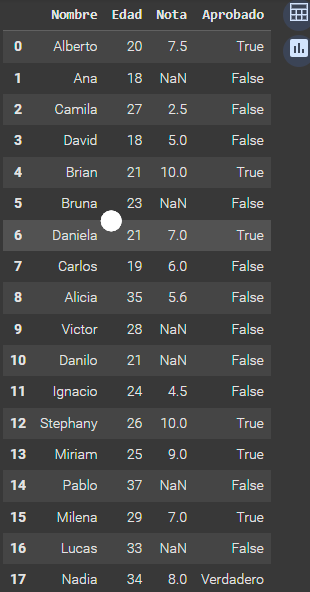
- Verifica si la base de datos contiene datos nulos y, en caso de tenerlos, realiza el tratamiento de estos datos nulos de la manera que consideres más coherente con la situación.
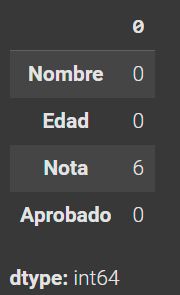
datos.isnull().sum() # Suma la cantidad de datos nulos
datos = datos.fillna(0) #Asignamos el valor de 0 a los datos nulos
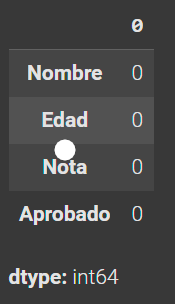
datos.isnull().sum() # Realizamos de nuevo el conteo de los datos nulos observando que ya no existen ya que se les dio el valor de 0
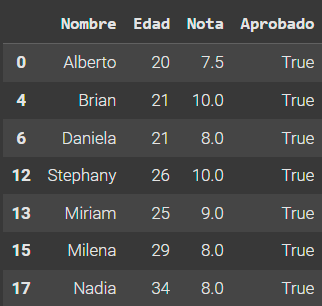
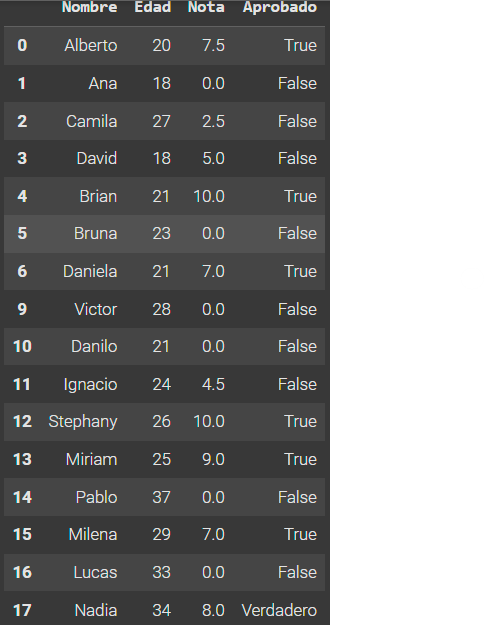
 2. Los estudiantes "Alicia" y "Carlos" ya no forman parte del grupo. Por lo tanto, elimínalos de la base de datos.
2. Los estudiantes "Alicia" y "Carlos" ya no forman parte del grupo. Por lo tanto, elimínalos de la base de datos.
# Guardamos los índices de las filas a eliminar en una variable
alumnosAEliminar = datos.query('Nombre == "Alicia" | Nombre == "Carlos"').index
# Eliminamos las filas correspondientes a los estudiantes "Alicia" y "Carlos"
datos.drop(alumnosAEliminar, axis=0, inplace=True)
datos # verificamos y observamos que los dos alumnos ya fueron eliminados
 3. Aplica un filtro que seleccione solo a los estudiantes que fueron aprobados.
3. Aplica un filtro que seleccione solo a los estudiantes que fueron aprobados.
# Reemplazar Verdadero por True
datos['Aprobado'] = datos['Aprobado'].replace({'Verdadero': 'True'})
# Creamos una variable en la que se muestran solamente los alumnos aprobados
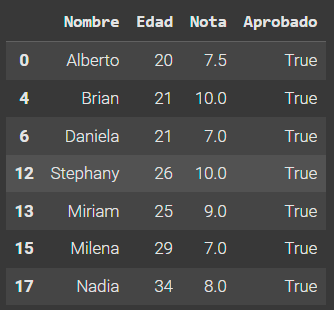
seleccion = datos.query('Aprobado == "True"')
seleccion
 4. Guarda el DataFrame que contiene solo a los estudiantes aprobados en un archivo CSV llamado "alumnos_aprobados.csv".
4. Guarda el DataFrame que contiene solo a los estudiantes aprobados en un archivo CSV llamado "alumnos_aprobados.csv".
# Guardamos el DataFrame resultante del desafío 3 en una variable:
alumnosAprobados = seleccion
alumnosAprobados
# Usamos el método to_csv para guardarlo en formato CSV
alumnosAprobados.to_csv('alumnos_aprobados.csv', index=False)
Extra: Al revisar las calificaciones de los estudiantes aprobados, notamos que algunas calificaciones eran incorrectas. Las estudiantes que obtuvieron una calificación de 7.0, en realidad tenían un punto extra que no se contabilizó. Por lo tanto, reemplaza las calificaciones de 7.0 en la base de datos por 8.0. Consejo: busca el método replace.
alumnosAprobados = alumnosAprobados.replace(7.0, 8.0)
alumnosAprobados