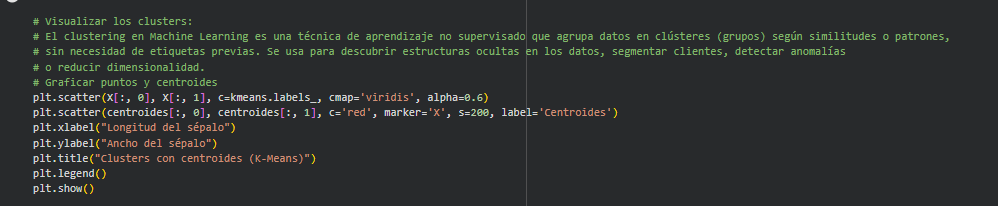
¡Hola Cristian, espero que estés bien!
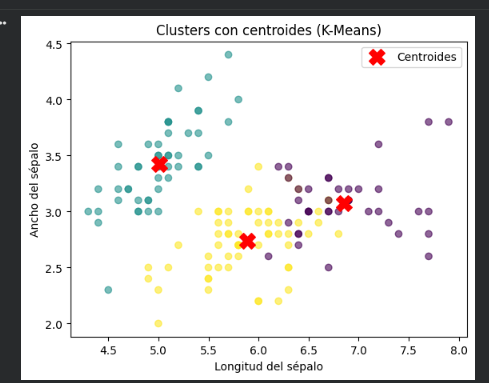
Para identificar patrones y agrupamientos naturales en un conjunto de datos, como mencionaste, el clustering es una técnica muy útil. El algoritmo K-Means es uno de los más populares para este propósito. En tu gráfico, los puntos representan los datos y las cruces rojas son los centroides de cada clúster, que indican el centro de cada grupo identificado por el algoritmo.
Para reducir la complejidad de los datos mientras mantienes la información relevante, puedes usar técnicas de reducción de dimensionalidad como el Análisis de Componentes Principales (PCA). PCA transforma los datos en un espacio de menos dimensiones, conservando las características más importantes. Esto es útil para visualizar datos y mejorar el rendimiento de otros algoritmos de machine learning.
Aquí tienes un ejemplo básico de cómo podrías aplicar K-Means y PCA al conjunto de datos Iris:
K-Means:
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3)
kmeans.fit(X)
clusters = kmeans.predict(X)
PCA:
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
Visualización:
Puedes visualizar los resultados como lo has hecho, usando matplotlib para graficar los datos y los centroides.
Espero que estos pasos te ayuden a experimentar con los algoritmos y entender mejor cómo identificar patrones y reducir la dimensionalidad en tus datos. ¡Bons estudios!