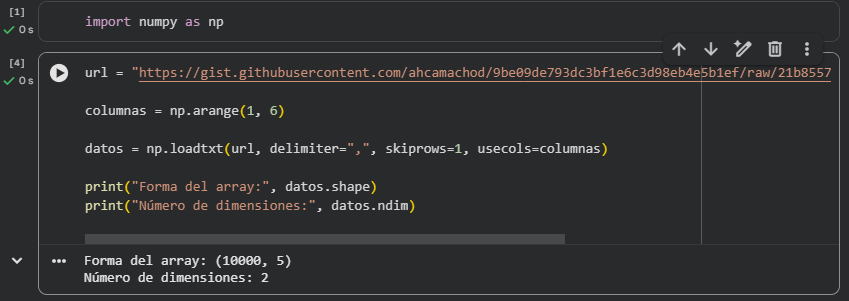
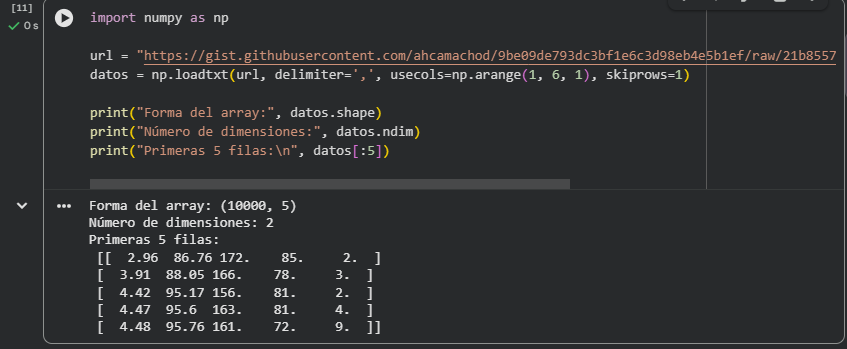
En esta actividad cargamos un dataset real desde un enlace en GitHub utilizando la función np.loadtxt de NumPy. Para preparar correctamente los datos, aplicamos los parámetros skiprows=1 (para omitir la primera fila con los encabezados) y usecols=np.arange(1,6) (para ignorar la primera columna con texto y quedarnos solo con las columnas numéricas). De esta manera, obtuvimos un array con 10,000 filas y 5 columnas, lo que verificamos con el atributo shape. También confirmamos que el array es bidimensional usando ndim.