Hola Andrés,
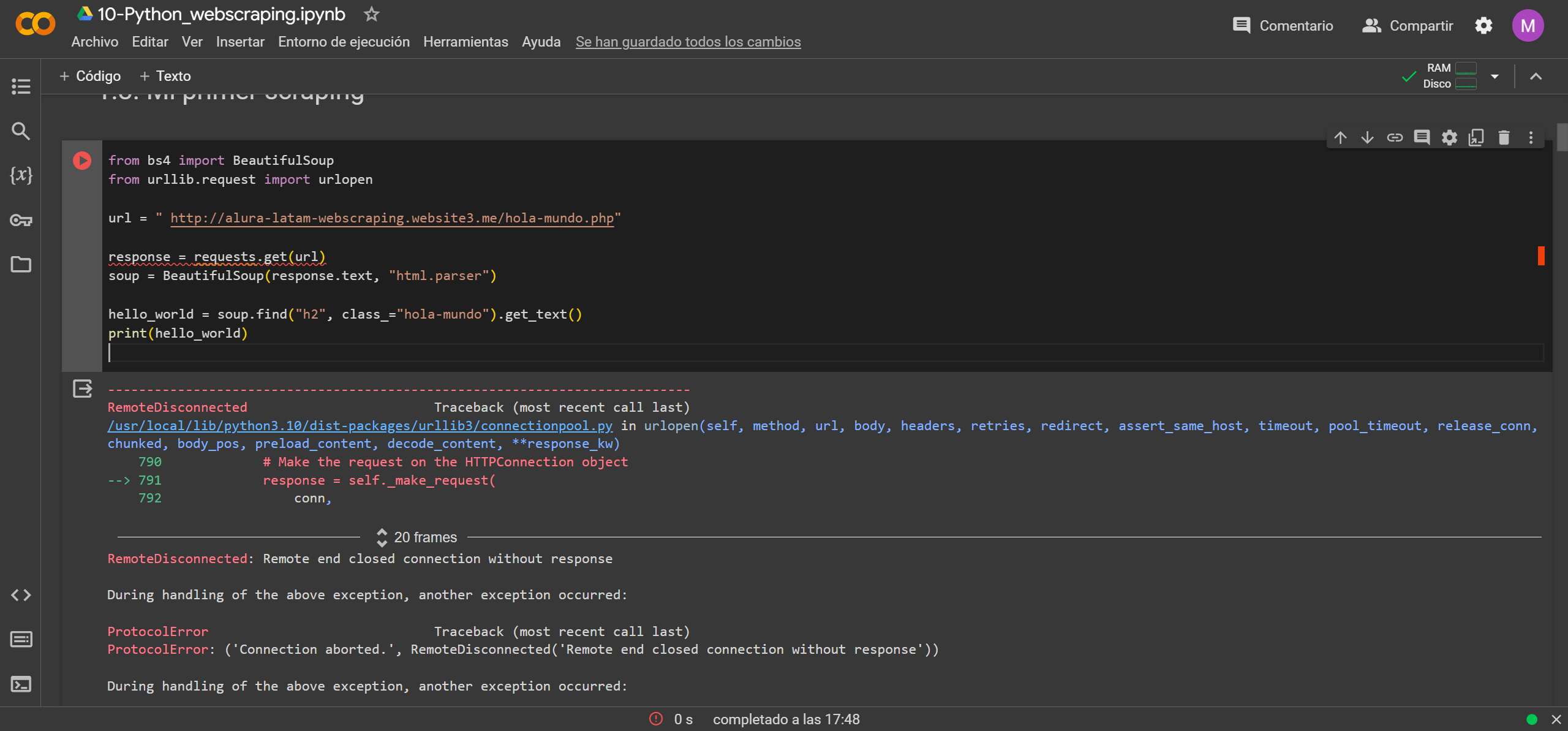
Gracias por tu pregunta. Parece que estás teniendo problemas para extraer el primer "Hello World!!!" de una página web utilizando Web Scraping. Según el contexto que proporcionaste, parece que estás siguiendo un ejercicio en el que se utiliza la etiqueta h1 con el id "hello-world", pero en la página actualizada que estás utilizando, la etiqueta es h2 con la clase "hello-world".
Para extraer el primer "Hello World!!!" en este caso, puedes utilizar el siguiente código:
from bs4 import BeautifulSoup
import requests
url = "http://alura-latam-webscraping.website3.me/"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
hello_world = soup.find("h2", class_="hello-world").get_text()
print(hello_world)
Este código utiliza la biblioteca BeautifulSoup para analizar el HTML de la página y encuentra la etiqueta h2 con la clase "hello-world". Luego, utiliza el método get_text() para obtener el texto dentro de la etiqueta.
Espero que esto resuelva tu duda. Si tienes alguna otra pregunta, no dudes en preguntar.
¡Espero haber ayudado y buenos estudios!