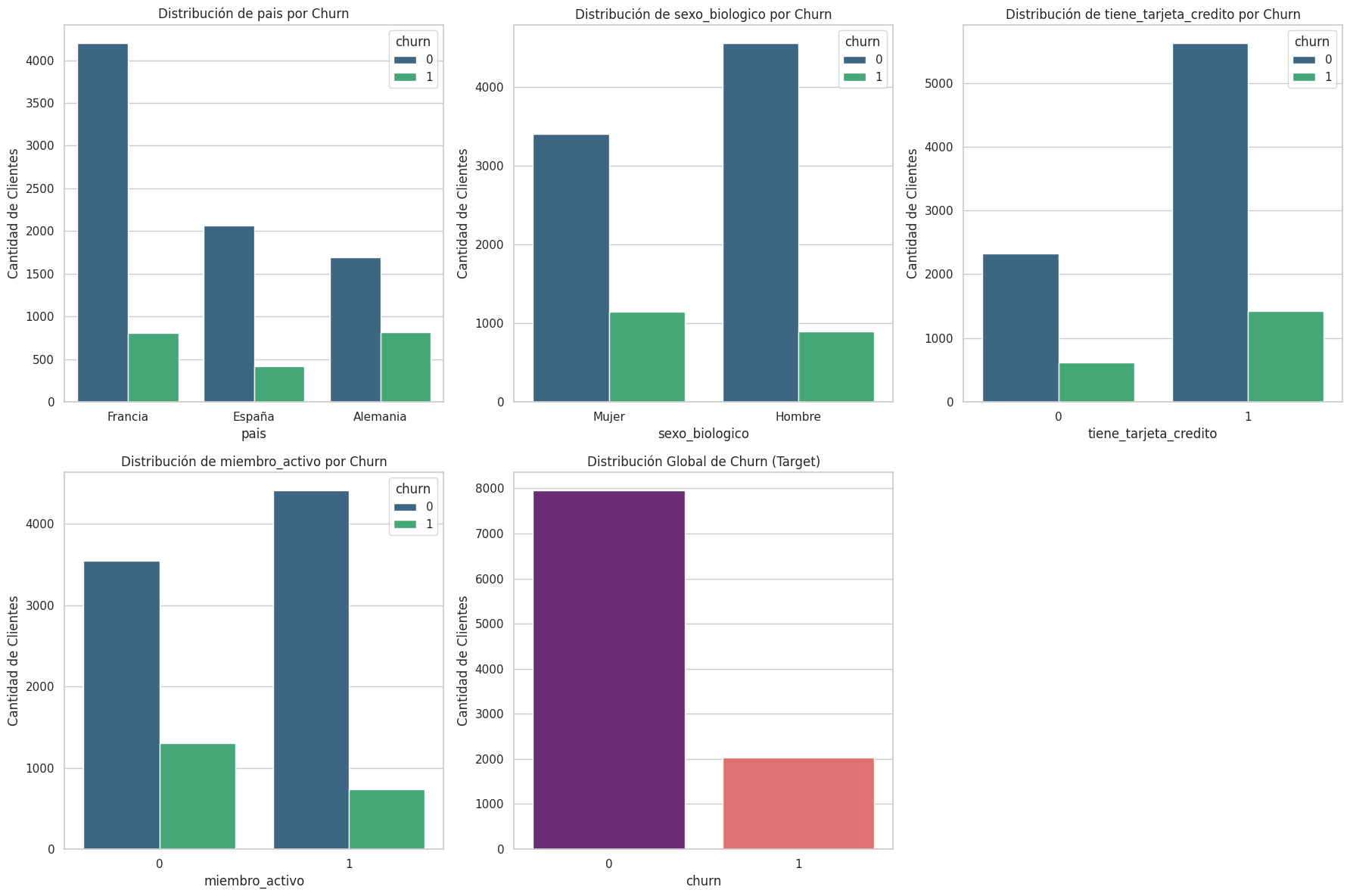Los desafíos siguen una secuencia de tareas, sirviendo como un proyecto secundario, que se realizará a lo largo de las clases del curso. Para realizar los desafíos, descarga la Base de datos - Desafío.
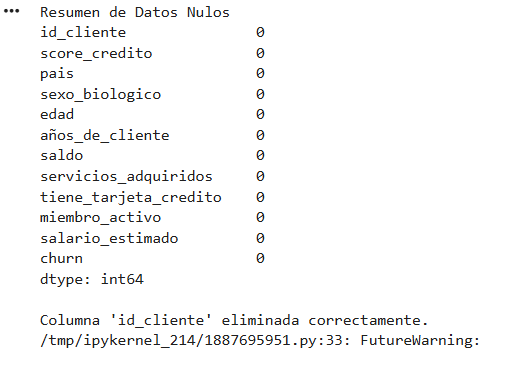
1 - La primera etapa en un proyecto de Machine Learning es la obtención de datos. A partir de esta obtención, podemos leer los datos para construir un modelo. Como tarea inicial, realiza la lectura de la base de datos y verifica la presencia de datos nulos. Además, elimina la columna 'id_cliente', ya que este tipo de información única para cada fila no es útil para su uso en modelos de machine learning.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# estilo para los gráficos
sns.set_theme(style="whitegrid")
df = pd.read_csv('/content/churn.csv')
print("Resumen de Datos Nulos")
print(df.isnull().sum())
# Eliminación de id_cliente
if 'id_cliente' in df.columns:
df.drop('id_cliente', axis=1, inplace=True)
print("\nColumna 'id_cliente' eliminada correctamente.")
2 - Después de leer los datos, es importante conocer los datos, revisando inconsistencias y entendiendo el comportamiento de cada una de las columnas. En esta tarea, realiza un análisis exploratorio utilizando gráficos para las variables categóricas de la base de datos, incluyendo la variable objetivo churn. Para estas variables, se pueden utilizar gráficos de barras para contar las categorías y hacer un agrupamiento por colores de acuerdo con las categorías de la variable objetivo.
# Identificamos las variables categóricas
cat_cols = ['pais', 'sexo_biologico', 'tiene_tarjeta_credito', 'miembro_activo', 'churn']
plt.figure(figsize=(18, 12))
for i, col in enumerate(cat_cols):
plt.subplot(2, 3, i+1)
if col != 'churn':
# Agrupamos por la variable objetivo
sns.countplot(data=df, x=col, hue='churn', palette='viridis')
plt.title(f'Distribución de {col} por Churn')
else:
sns.countplot(data=df, x=col, palette='magma')
plt.title('Distribución Global de Churn (Target)')
plt.xlabel(col)
plt.ylabel('Cantidad de Clientes')
plt.tight_layout()
plt.show()
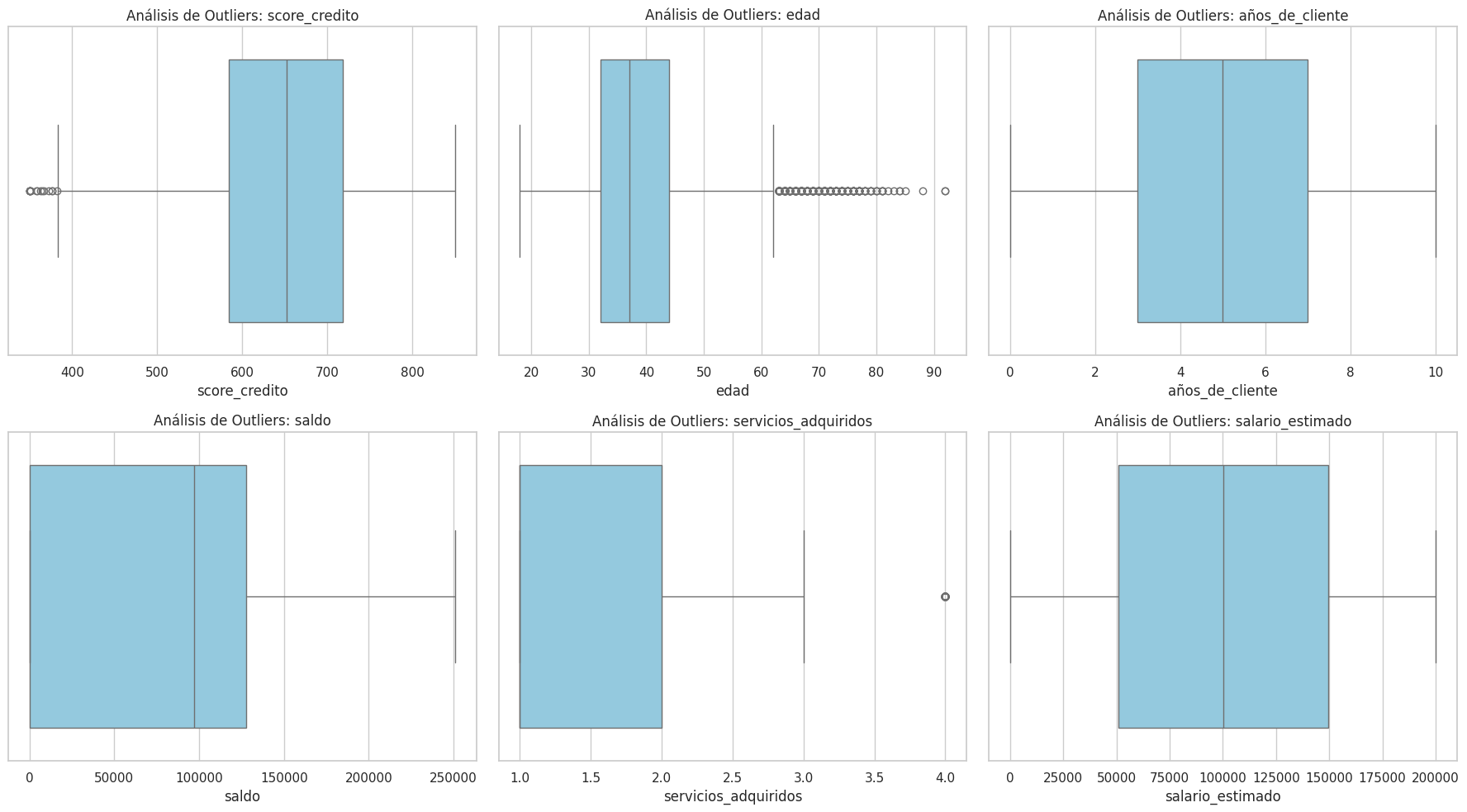
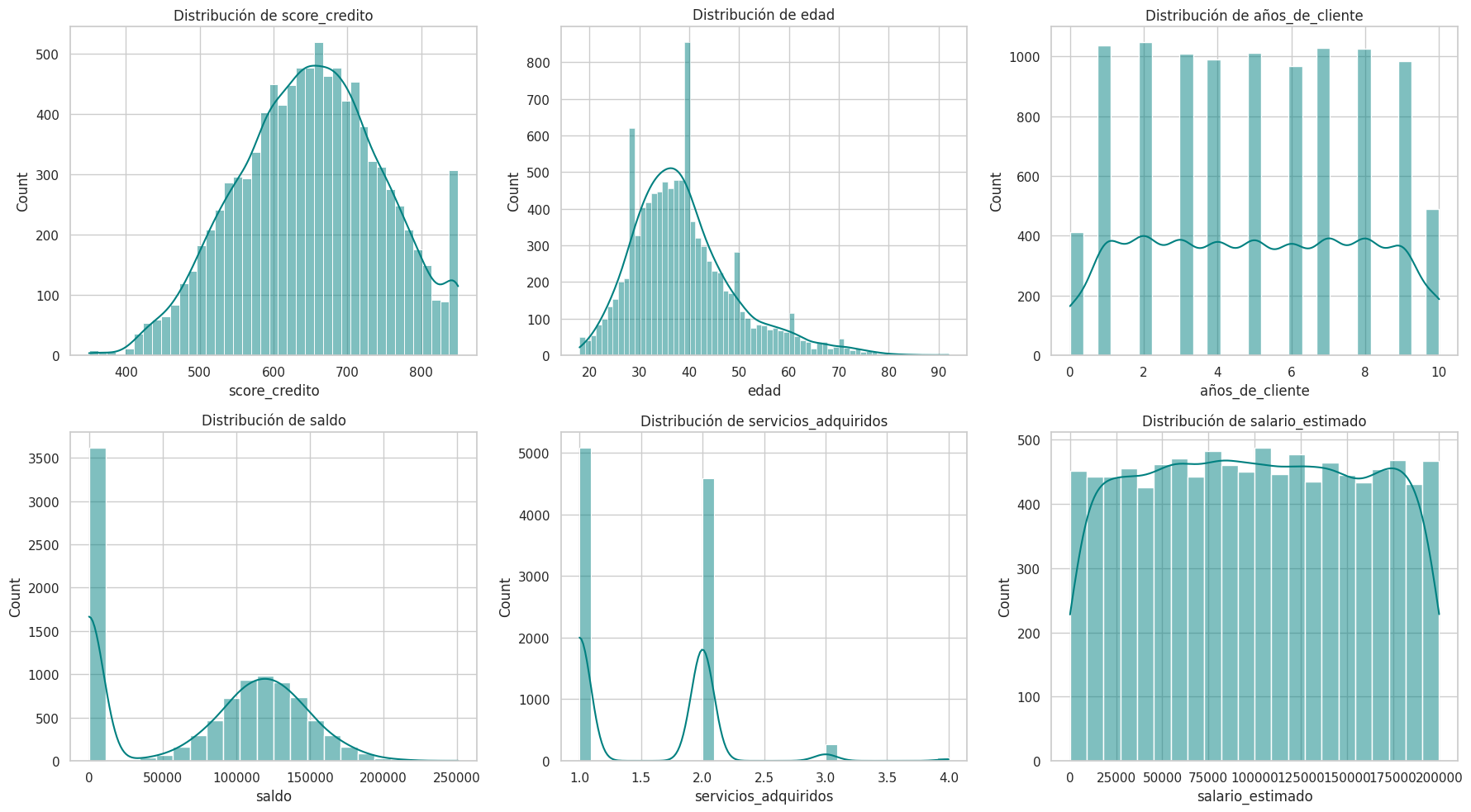
3 - Después de explorar las variables categóricas, es el turno de las variables numéricas. Construye gráficos de distribución como boxplots o histogramas para analizar el comportamiento de los valores numéricos y verificar si hay valores inconsistentes.
num_cols = ['score_credito', 'edad', 'años_de_cliente', 'saldo', 'servicios_adquiridos', 'salario_estimado']
# Visualización con Boxplots
plt.figure(figsize=(18, 10))
for i, col in enumerate(num_cols):
plt.subplot(2, 3, i+1)
sns.boxplot(x=df[col], color='skyblue')
plt.title(f'Análisis de Outliers: {col}')
plt.tight_layout()
plt.show()
# Visualización con Histogramas
plt.figure(figsize=(18, 10))
for i, col in enumerate(num_cols):
plt.subplot(2, 3, i+1)
sns.histplot(df[col], kde=True, color='teal')
plt.title(f'Distribución de {col}')
plt.tight_layout()
plt.show()