La separación de los datos entre conjunto de entrenamiento y prueba es esencial para comprender si un modelo está logrando aprender los patrones y generalizar a nuevos datos. En esta tarea, realiza la división de la base de datos entre entrenamiento y prueba de forma estratificada.
Un modelo base es muy importante para definir un criterio de comparación para modelos más complejos. En esta etapa, crea un modelo base con el DummyClassifier y encuentra la tasa de acierto con el método score.
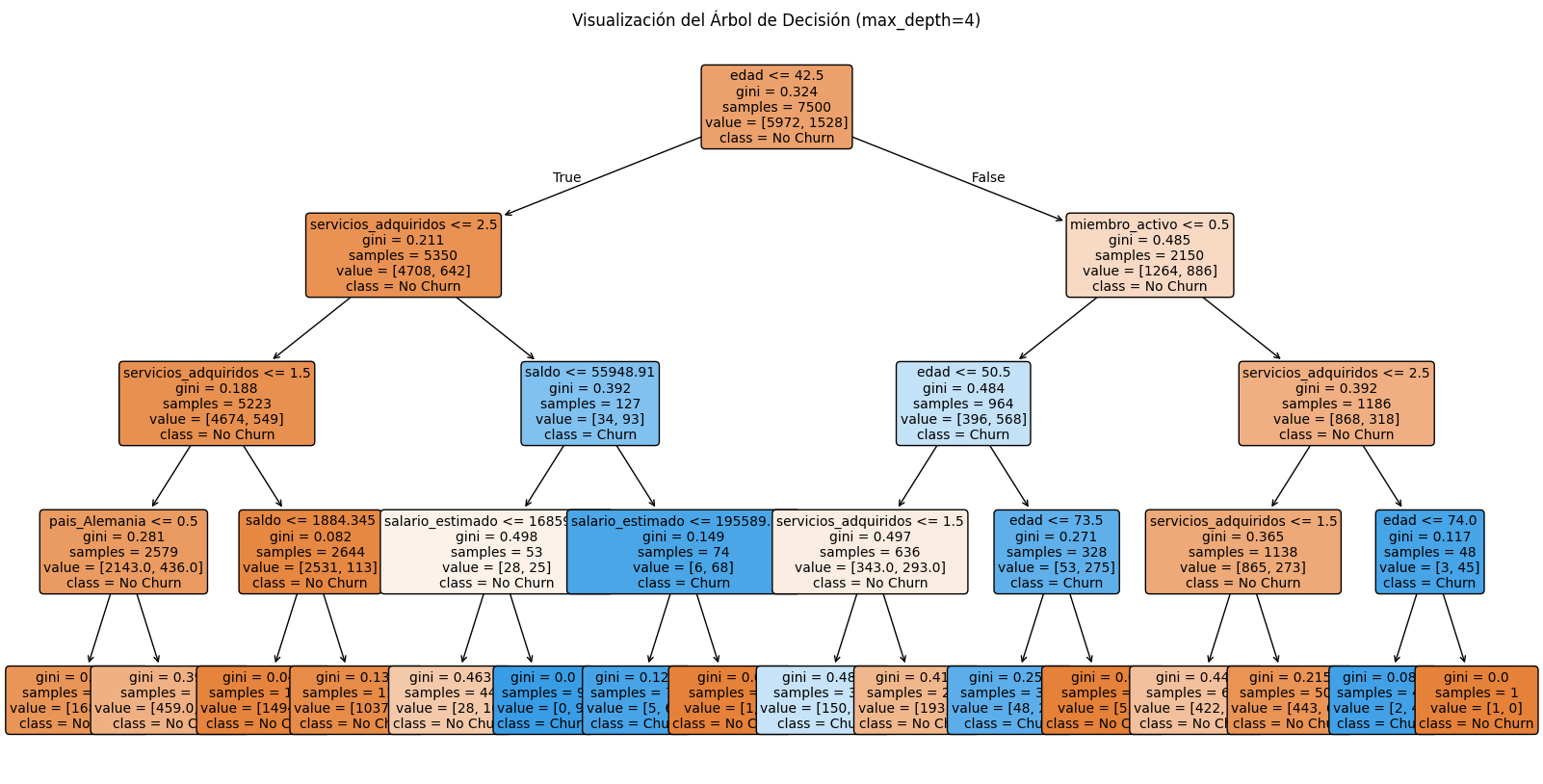
El árbol de decisión es un algoritmo que realiza las clasificaciones a partir de decisiones simples tomadas a partir de los datos. Debemos tener cierto cuidado de no utilizar una profundidad muy grande, porque esto puede provocar un sobreajuste del modelo a los datos de entrenamiento. En este desafío, crea un modelo de árbol de decisión con el parámetro max_depth=4, evalúa el desempeño del modelo en los datos de prueba y visualiza las decisiones del árbol usando el método plot_tree.
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder, LabelEncoder
from sklearn.dummy import DummyClassifier
from sklearn.tree import DecisionTreeClassifier, plot_tree
df = pd.read_csv('/content/churn.csv')
if 'id_cliente' in df.columns:
df = df.drop(columns=['id_cliente'])
X = df.drop(columns=['churn'])
y = df['churn']
# Transformación de variables categóricas explicativas
cat_cols = ['pais', 'sexo_biologico']
ohe = OneHotEncoder(drop='if_binary', sparse_output=False)
X_cat = ohe.fit_transform(X[cat_cols])
X_cat_df = pd.DataFrame(X_cat, columns=ohe.get_feature_names_out(cat_cols))
X_final = pd.concat([X.drop(columns=cat_cols).reset_index(drop=True), X_cat_df], axis=1)
# Transformación de variable objetivo
le = LabelEncoder()
y_final = le.fit_transform(y)
# División Estratificada
# Usamos stratify=y_final para mantener la proporción de Churn en ambos conjuntos
X_train, X_test, y_train, y_test = train_test_split(
X_final, y_final, test_size=0.25, random_state=42, stratify=y_final
)
# Modelo Dummy (Base)
dummy = DummyClassifier(strategy='most_frequent')
dummy.fit(X_train, y_train)
dummy_score = dummy.score(X_test, y_test)
# Árbol de Decisión
# Limitamos la profundidad a 4 para evitar el sobreajuste (overfitting)
dt = DecisionTreeClassifier(max_depth=4, random_state=42)
dt.fit(X_train, y_train)
dt_score = dt.score(X_test, y_test)
# RESULTADOS
print(f"Exactitud del Modelo Dummy: {dummy_score:.4f}")
print(f"Exactitud del Árbol de Decisión: {dt_score:.4f}")
# Visualización del Árbol
plt.figure(figsize=(20, 10))
plot_tree(dt,
feature_names=X_final.columns.tolist(),
class_names=['No Churn', 'Churn'],
filled=True,
rounded=True,
fontsize=10)
plt.title("Visualización del Árbol de Decisión (max_depth=4)")
plt.show()