¡Hola Estudiante, espero que estés bien!
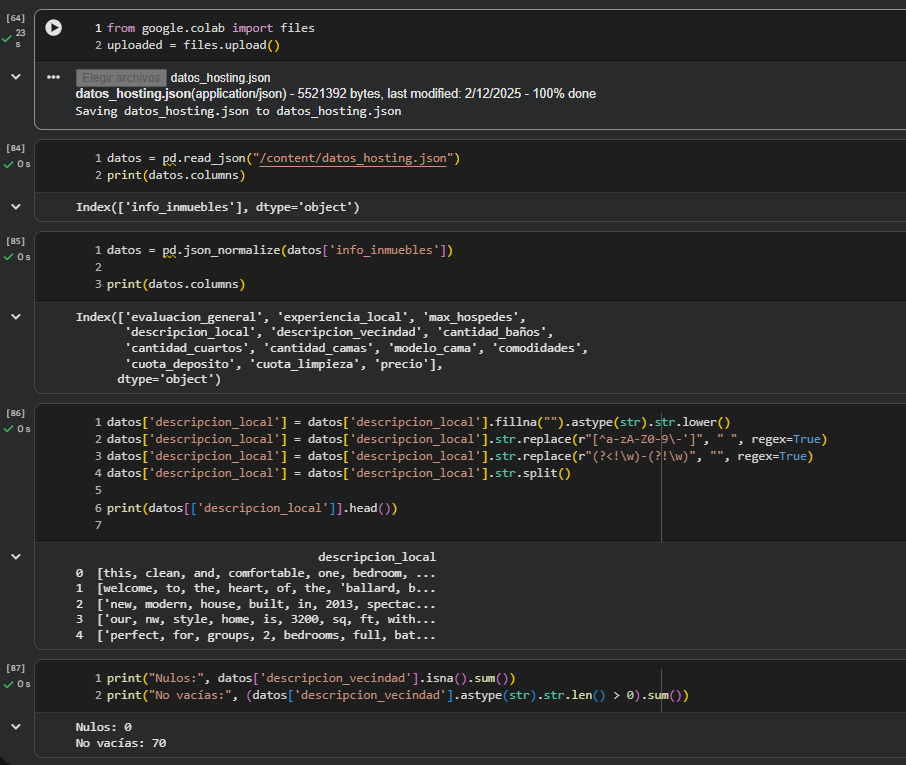
Parece que ya has hecho un gran trabajo normalizando y tokenizando la columna descripcion_local. Ahora, para la columna descripcion_vecindad, aunque mencionas que está vacía en todos los registros, podrías intentar el mismo proceso para asegurarte de que no haya datos ocultos o formateados de manera diferente que puedan ser procesados.
Aquí tienes un ejemplo de cómo podrías hacerlo:
# Asegúrate de que los valores nulos sean reemplazados por una cadena vacía
datos['descripcion_vecindad'] = datos['descripcion_vecindad'].fillna("").astype(str).str.lower()
# Elimina caracteres no deseados usando expresiones regulares
datos['descripcion_vecindad'] = datos['descripcion_vecindad'].str.replace(r"[^a-zA-Z0-9\s]", " ", regex=True)
# Divide el texto en listas de palabras
datos['descripcion_vecindad'] = datos['descripcion_vecindad'].str.split()
# Muestra los primeros registros para verificar
print(datos[['descripcion_vecindad']].head())
Si después de esto la columna sigue vacía, entonces es posible que realmente no haya datos útiles en ella. Sin embargo, este proceso te ayudará a confirmar que no hay información procesable.
Espero que esto te ayude y buenos estudios!