Prompt:
Actúa como un científico de datos experto en Python y análisis exploratorio de datos (EDA).
Estoy trabajando en un proyecto de Ciencia de Datos sobre consumo de energía eléctrica mundial.
Tengo la siguiente URL que contiene un archivo CSV:
url_consumo = 'https://gist.githubusercontent.com/ahcamachod/fe75f2d71ae7b992dcdc9c6587f6e4d0/raw/c6ab400346ff9c30fc492b9233fa3a301d489acf/resumen_mundial.csv'
Objetivos:
Escribe código en Python usando la biblioteca pandas para importar los datos desde la URL y almacenarlos en un DataFrame llamado df_consumo.
Escribe código para realizar una exploración inicial de los datos, que incluya:
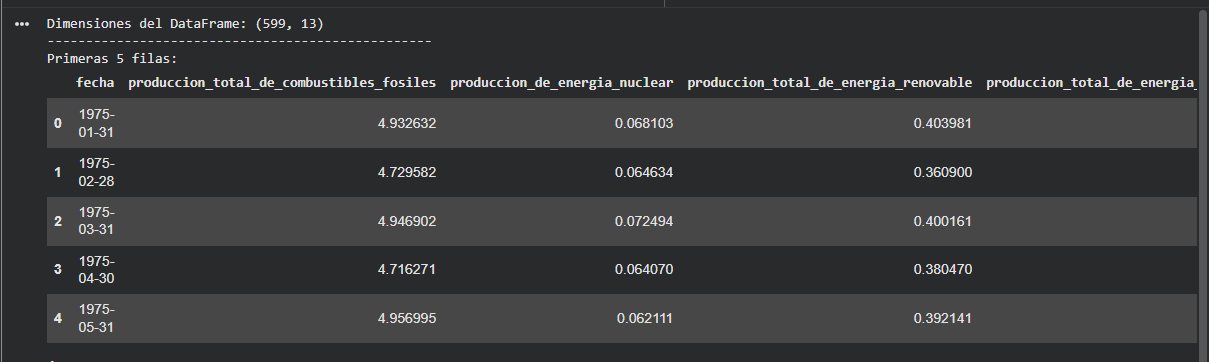
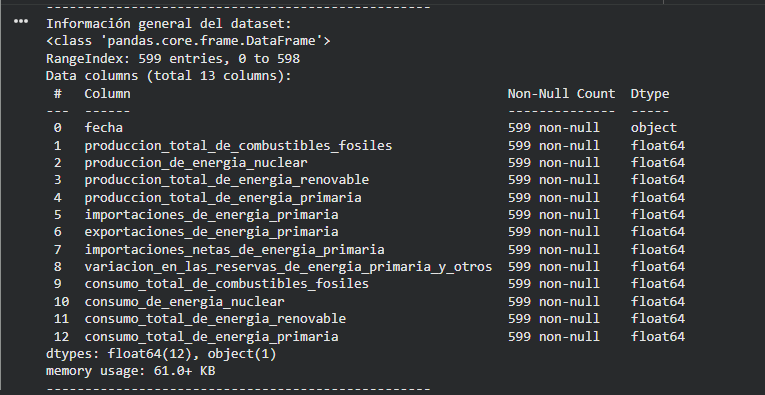
Dimensiones del DataFrame
Información general (tipos de datos y valores nulos)
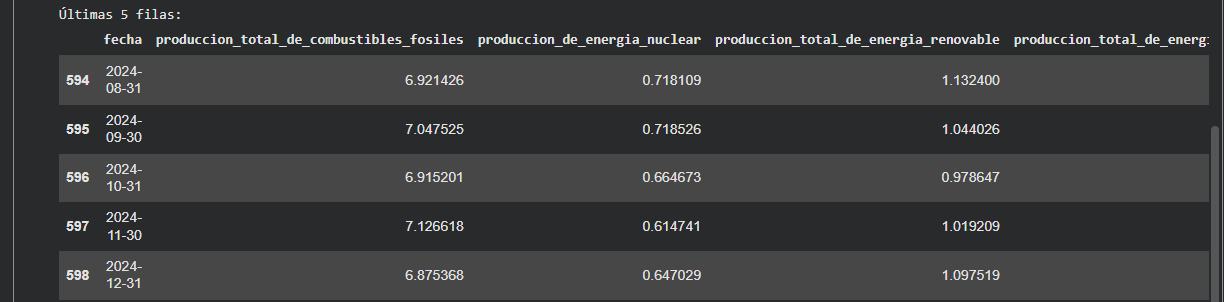
Visualización de las primeras y últimas filas
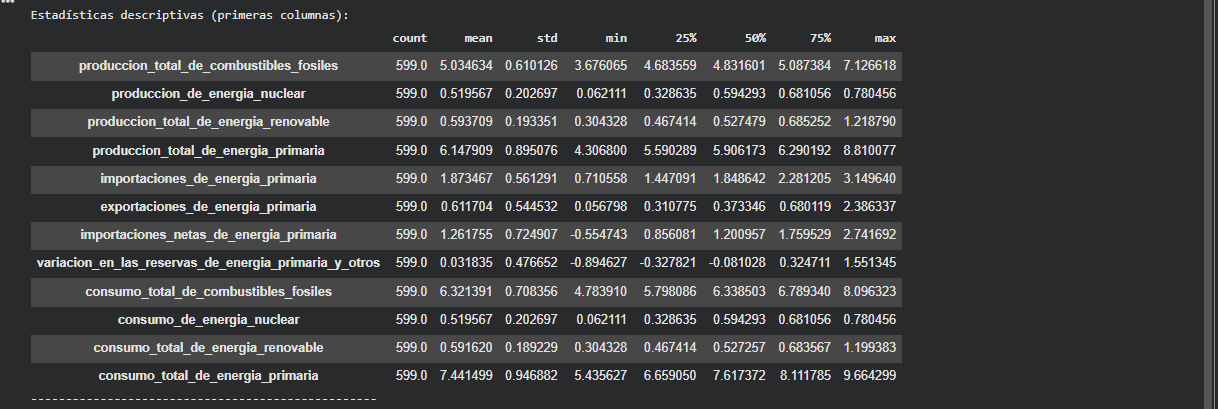
Estadísticas descriptivas
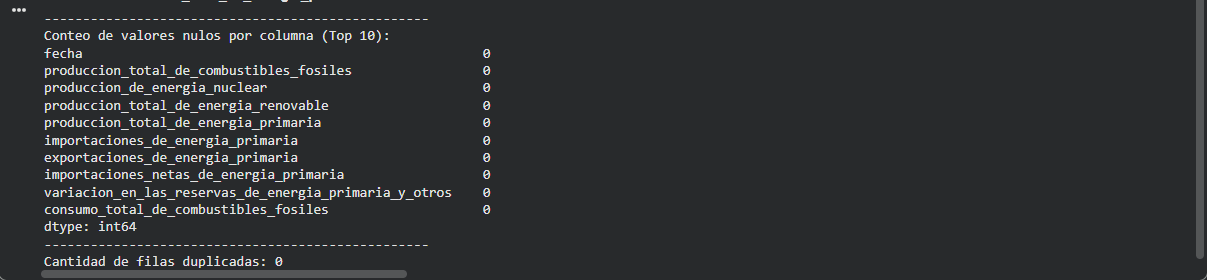
Identificación de valores nulos
Revisión de posibles duplicados
A partir de la exploración, proporciona una breve interpretación del conjunto de datos que ayude a comprender:
Qué representa cada fila
Qué tipo de variables contiene
Cómo están organizados los años de consumo
Diccionario de datos:
continente: Nombre del continente
pais: Nombre del país
1983, 1984, ..., 2024: Consumo de energía eléctrica en cuatrillones de BTU por año
resumen_mundial: Suma del consumo de energía a lo largo de los años
Devuelve únicamente código en Python bien comentado y una explicación clara de la exploración realizada.
Respuesta del prompt: