Muestro evidencia sobre la carga de datos
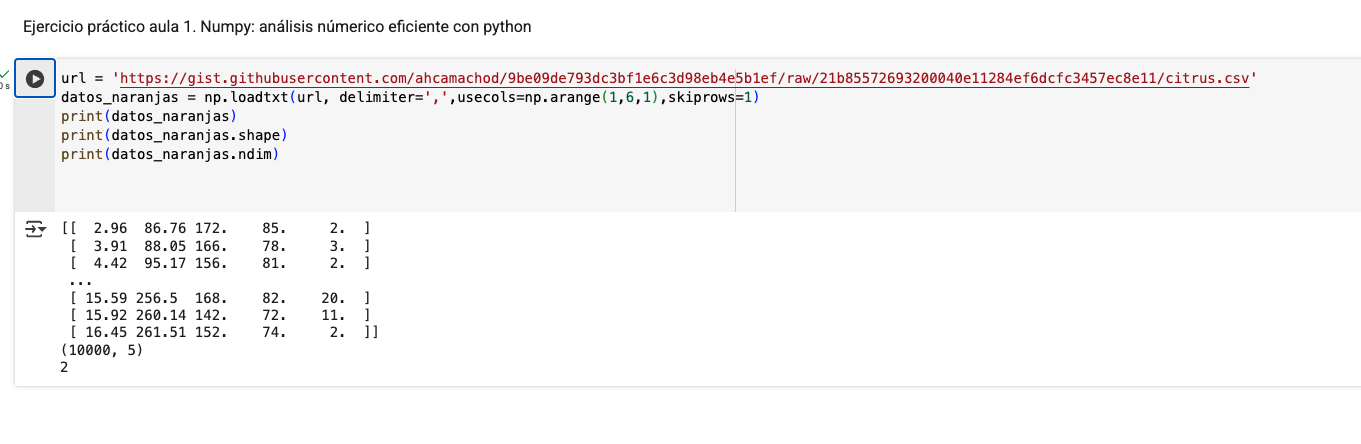

Muestro evidencia sobre la carga de datos


Hola, Jorge, espero que estés bien
Parece que has cargado los datos correctamente usando np.loadtxt. Veo que has especificado la URL del archivo CSV y has utilizado los parámetros delimiter=',', usecols=np.arange(1,6,1), y skiprows=1. Esto está en línea con lo que se solicita en el ejercicio.
Aquí hay un pequeño desglose de lo que hace cada parte:
delimiter=',': Esto indica que el archivo CSV está separado por comas.usecols=np.arange(1,6,1): Esto selecciona las columnas de la 1 a la 5 (excluyendo la primera columna, que es la 0).skiprows=1: Esto omite la primera fila del archivo, que generalmente contiene los encabezados.Tu código parece estar funcionando bien, ya que la salida muestra la forma del array (10000, 5) y el número de dimensiones 2, lo cual es correcto para un conjunto de datos con 10,000 filas y 5 columnas.
Si tienes alguna otra pregunta o necesitas más detalles sobre cómo manipular o analizar estos datos, no dudes en preguntar.
Espero haber ayudado y buenos estudios!