
Para el siguiente Desafío entrene el modelo con AutoML utilizando las sugerencias indicadas por el ejercicio y obtuve los siguiente resultados:
Entrenando el modelo con los nuevos ajustes para los hiperparametros
modelo_automl, baseline = oracle_automl.train(score_metric='f1', model_list=['AdaBoostClassifier', 'DecisionTreeClassifier', 'ExtraTreesClassifier', 'KNeighborsClassifier', 'LGBMClassifier', 'LinearSVC', 'LogisticRegression', 'RandomForestClassifier', 'SVC', 'XGBClassifier'], time_budget=0)Resultados del entrenamiento ordenados por Score de mayor a menor
oracle_automl.print_trials(max_rows=20, sort_column='Mean Validation Score')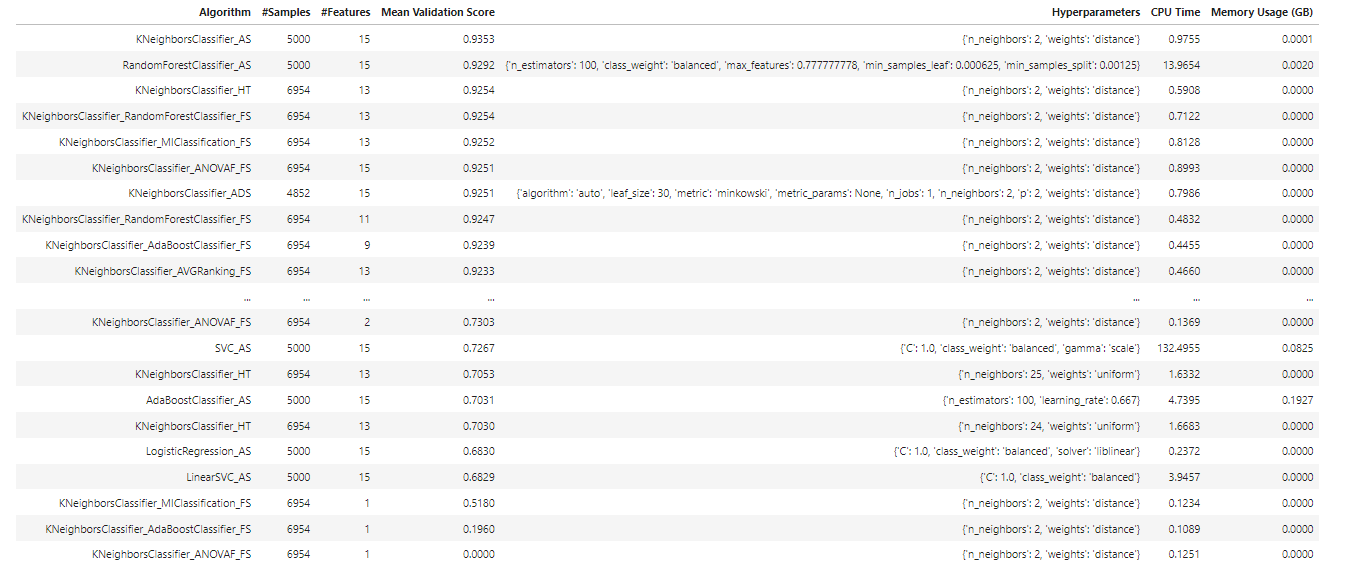 Clasificando los modelos por el score (f1)
Clasificando los modelos por el score (f1)
oracle_automl.visualize_algorithm_selection_trials()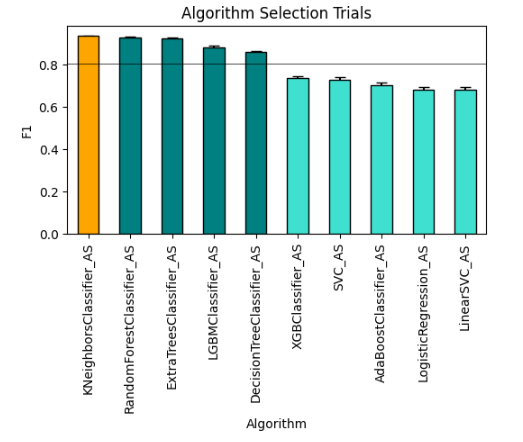
Características de nuestro mejor modelo seleccionado
modelo_automl.show_in_notebook()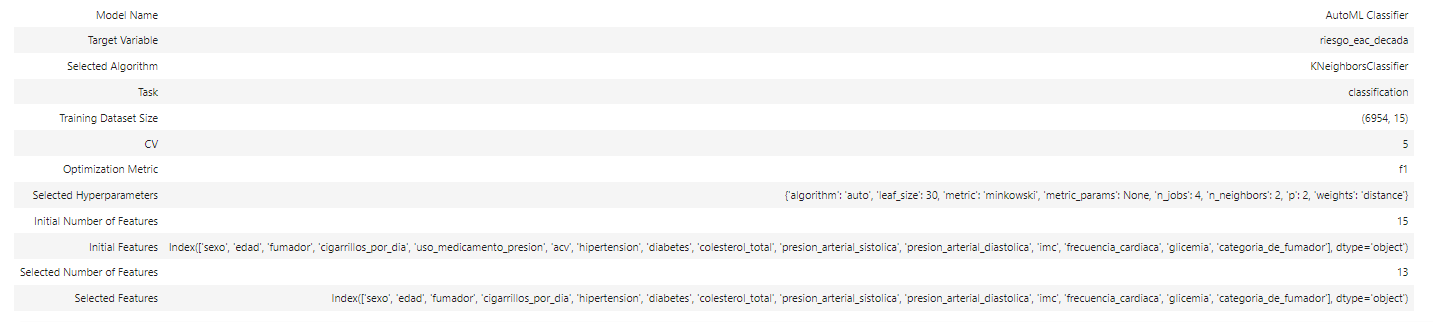
Analizando las métricas
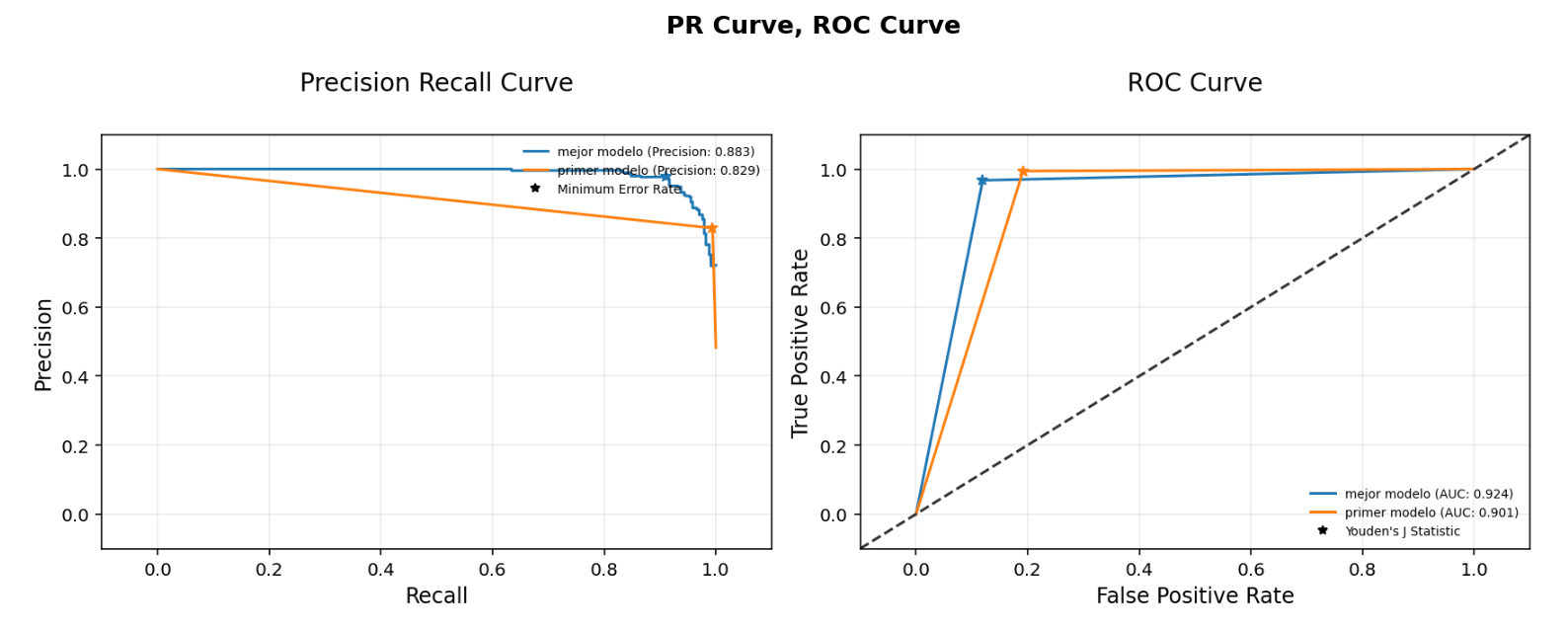
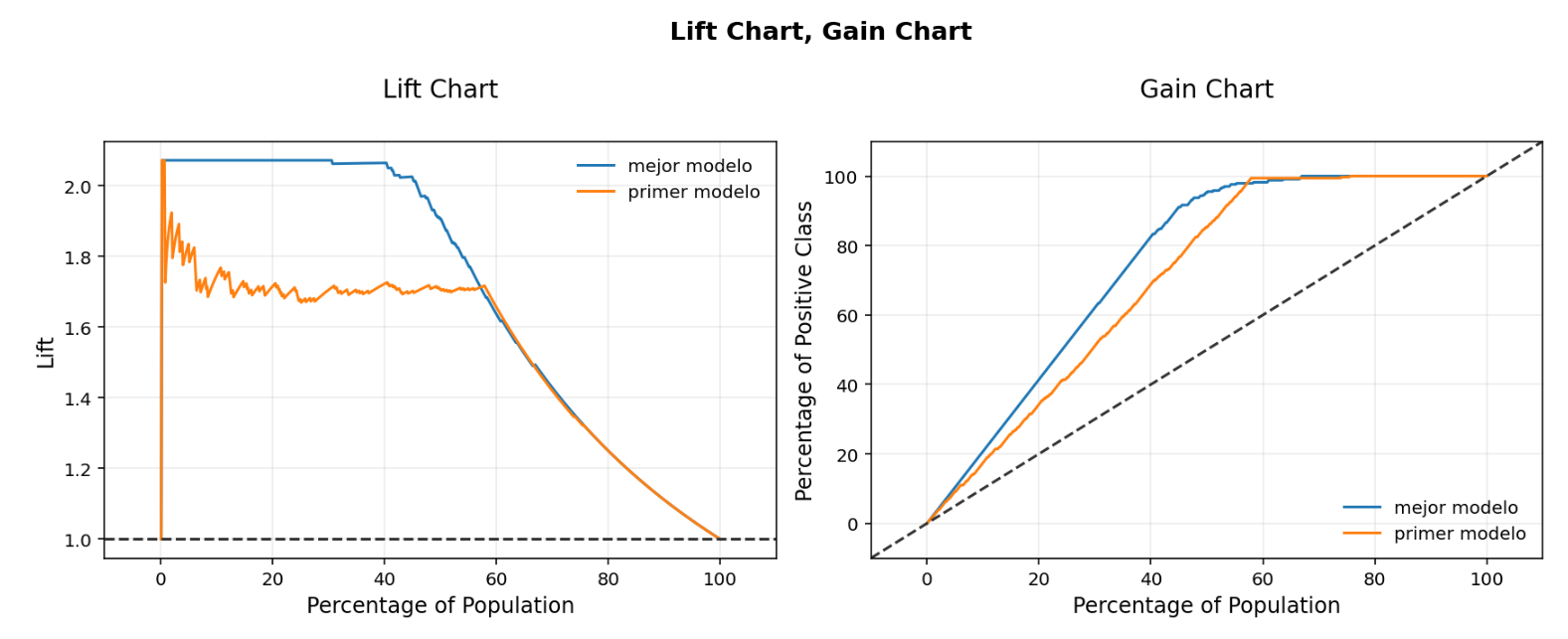
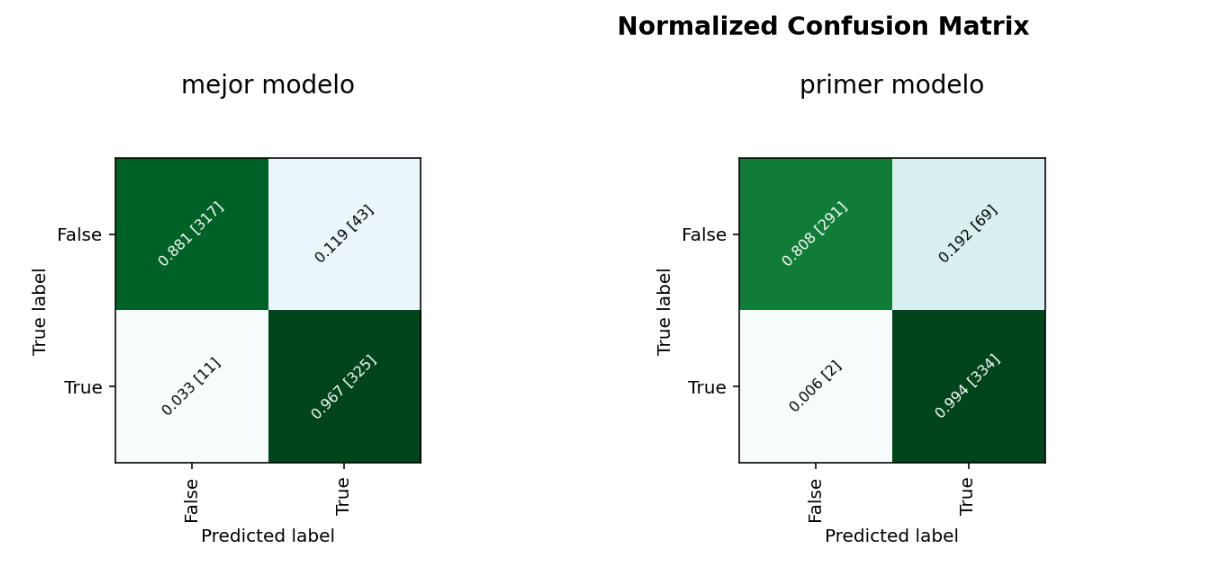
Conclusiones
Con los ajustes a los hiperparametros del entrenamiento hemos obtenido que el mejor modelo de clasificación es el de KNeighborsClassifierAS con un Score de 93.5%, este tan solo con una diferencia levemente mayor a los resultados que nos entregaba el modelo de RandomForestClassifier_AS el cual tiene un score de 92.9%. Esto lo podemos ver reflejado en los diferentes gráficos como por ejemplo el de matriz de confusión donde los datos obtenidos por el mejor modelo son exactamente los mismos a los que obtuvimos con el modelo de RandomForestClassifier_AS

