
Sé que un tema sobre esta misma pregunta ya está abierta, pero no ha tenido solución.
El ejercicio del video titulado Mi primer scraping esta realizado con otra página web, la cual posee detalles de url distintos a los que se presentan en la nueva página, por lo tanto, el aprendizaje es totalmente inútil ya que las formas de buscar no son las mismas.
Al respecto, mis dudas son respecto al código
from bs4 import BeautifulSoup
from urllib.request import urlopen
import pandas as pd
url = "https://alura-latam-webscraping.website3.me/"
response = urlopen(url)
html = response.read()
html
soup = BeautifulSoup(html, "html.parser")
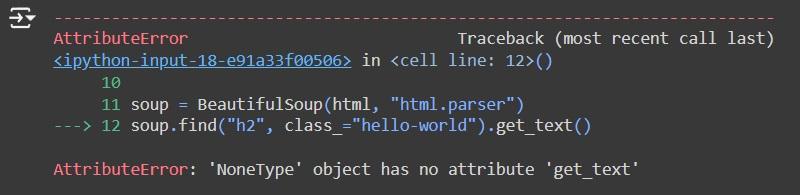
soup.find("h2", class_="hello-world").get_text()
Siguiendo las directrices del video, me da el siguiente error:
Luego, una de las instructoras dio el siguiente código:
from bs4 import BeautifulSoup
import requests
url = "http://alura-latam-webscraping.website3.me/"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
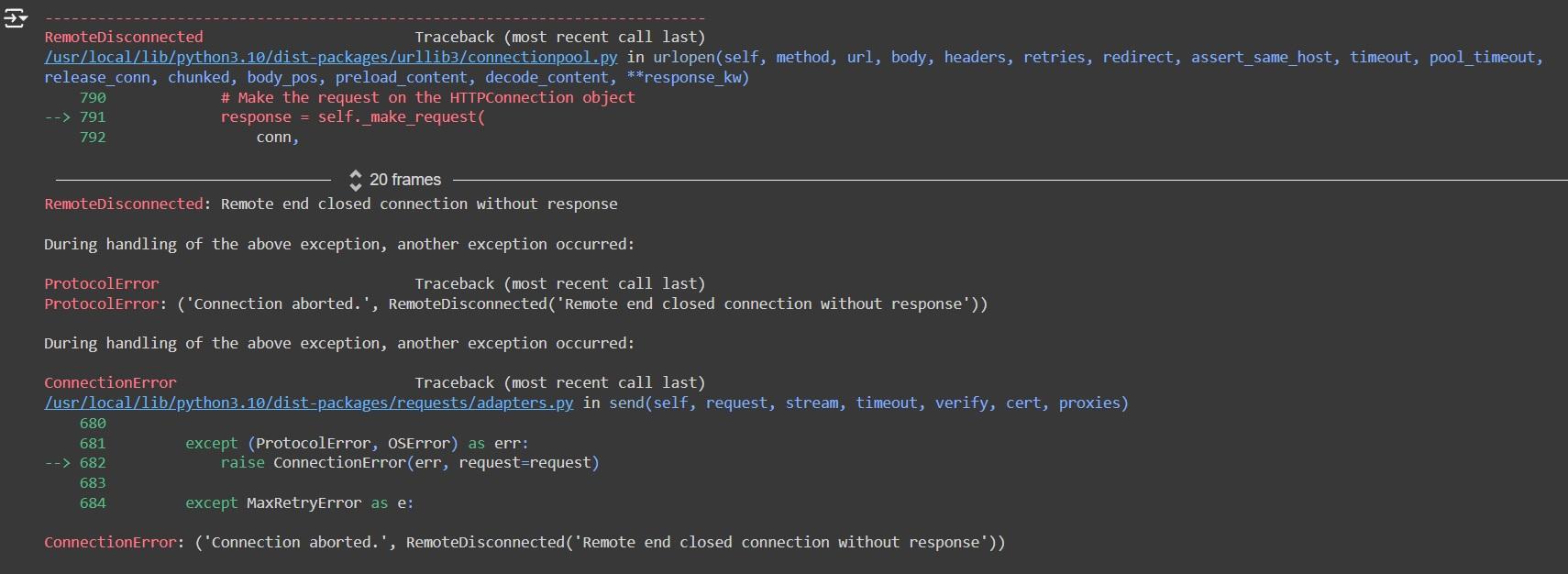
hello_world = soup.find("h2", class_="hello-world").get_text()
print(hello_world)
El cual da el siguiente error:
Respecto a esto, mis preguntas son las siguientes:
- ¿Cuáles son los errores que se comenten en ambos casos?
- ¿Qué se debe modificar?
- ¿Dónde puedo leer para entender respecto a las variables que se consideran en estas librerias?
Quedo atento.
Saludos.

