Hola, tengo la siguiente pregunt: ¿cómo supo el profe, en el video, que los outliers eran los datos mayores a 500.000?

Hola, tengo la siguiente pregunt: ¿cómo supo el profe, en el video, que los outliers eran los datos mayores a 500.000?


Hola Silvia,
En el video, el profesor identificó los outliers como los datos mayores a 500.000 al observar el box-plot de la columna "valor" del DataFrame. El box-plot es un gráfico estadístico que muestra la distribución de los datos y los valores atípicos.
En el box-plot, se pueden ver diferentes elementos como la mediana, los cuartiles y los límites inferior y superior. Los outliers son aquellos puntos que están fuera de estos límites. En este caso, el límite inferior es el primer cuartil (Q1) menos 1,5 veces el intervalo intercuartil (IIQ), y el límite superior es el tercer cuartil (Q3) más 1,5 veces el IIQ.
El profesor utilizó estos límites para seleccionar los registros que tenían un valor mayor a 500.000 y los consideró como outliers. Luego, creó un nuevo DataFrame sin estos outliers para poder trabajar con los datos corregidos.
Si este post te ayudó, por favor, marca como solucionado ✓.

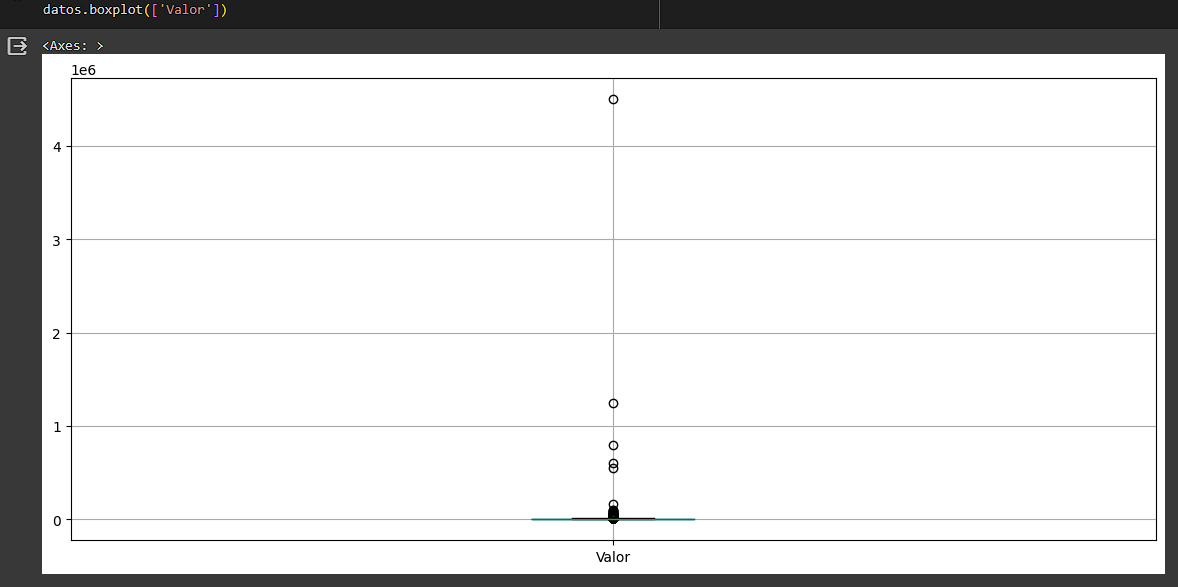
El eje ´y´ representa los valores pero en notación científica donde 1e6 se refiere a 1 por 10 elevado a la 6, es decir 1 millón, por lo cual los valores de ese eje son 0, 1, 2, 3 y 4 millones. Ahora si vemos el gráfico podemos ver que hay varios valores que exceden el límite superior por lo que esos son los outliers, sin embargo vemos que a partir de aproximadamente 0.5 (es decir 500.000) algunos pocos valores se disparan por lo que eliminaremos esos e interpretamos que los otros valores por debajo simplemente son valores de alquiler muy caros.