
A continuación se relaciona el codigo generado con asesoria de Luri inicialmente se corrio el codigo con los valores recomendados por Luri
alpha = 0.8
gamma = 0.95
epsilon = 1.0
epsilon_decay = 0.999
epsilon_min = 0.01
num_episodes = 20000
y posteriormente se corrio el codigo con los nuevos valores se desglosan a continuación dichos nuevos valores:
alpha = 0.9 # Agente aprende más rápido de cada experiencia
gamma = 0.95 # Mantener el factor de descuento
epsilon = 1.0 # Mantener la exploración inicial alta
epsilon_decay = 0.995 # La exploración disminuye un poco más lento, dando más tiempo para explorar
epsilon_min = 0.05 # Asegurar que siempre haya un poco más de exploración mínima
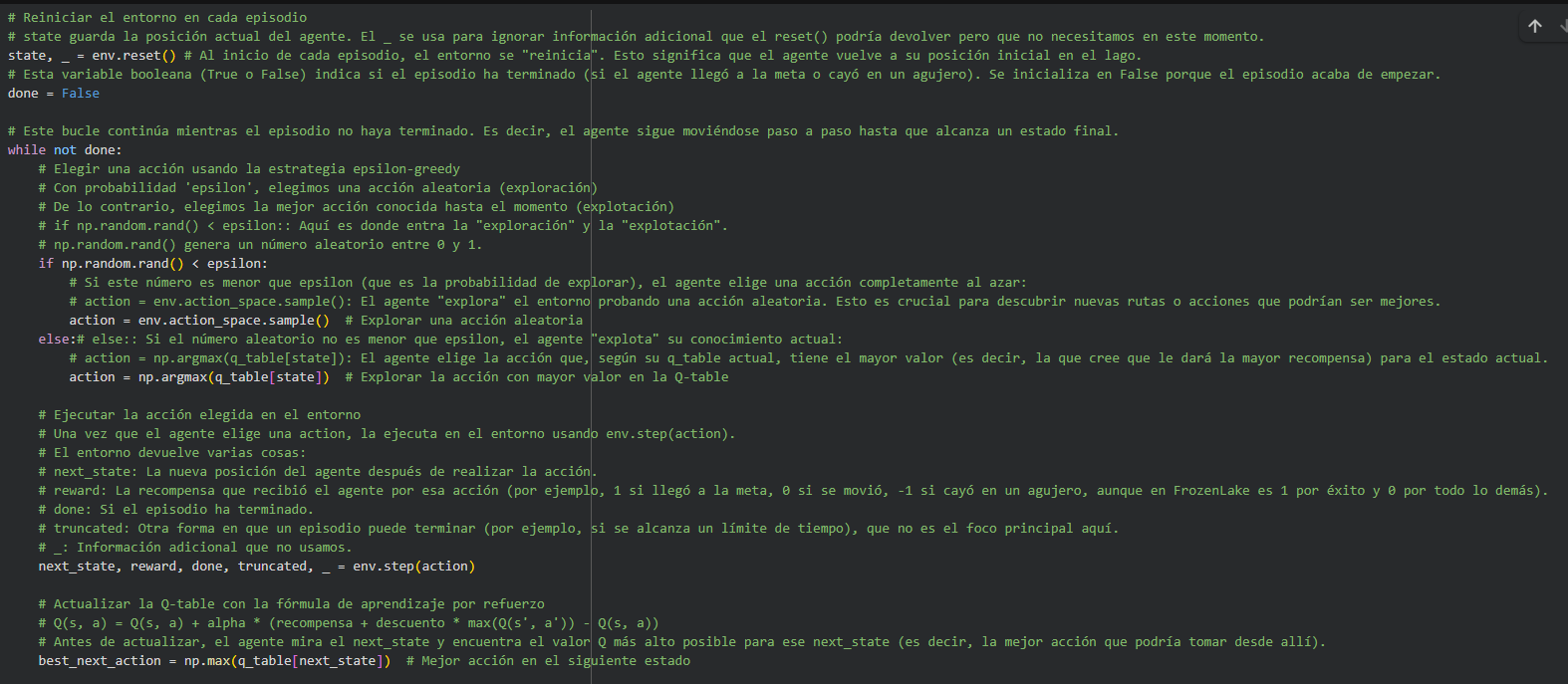
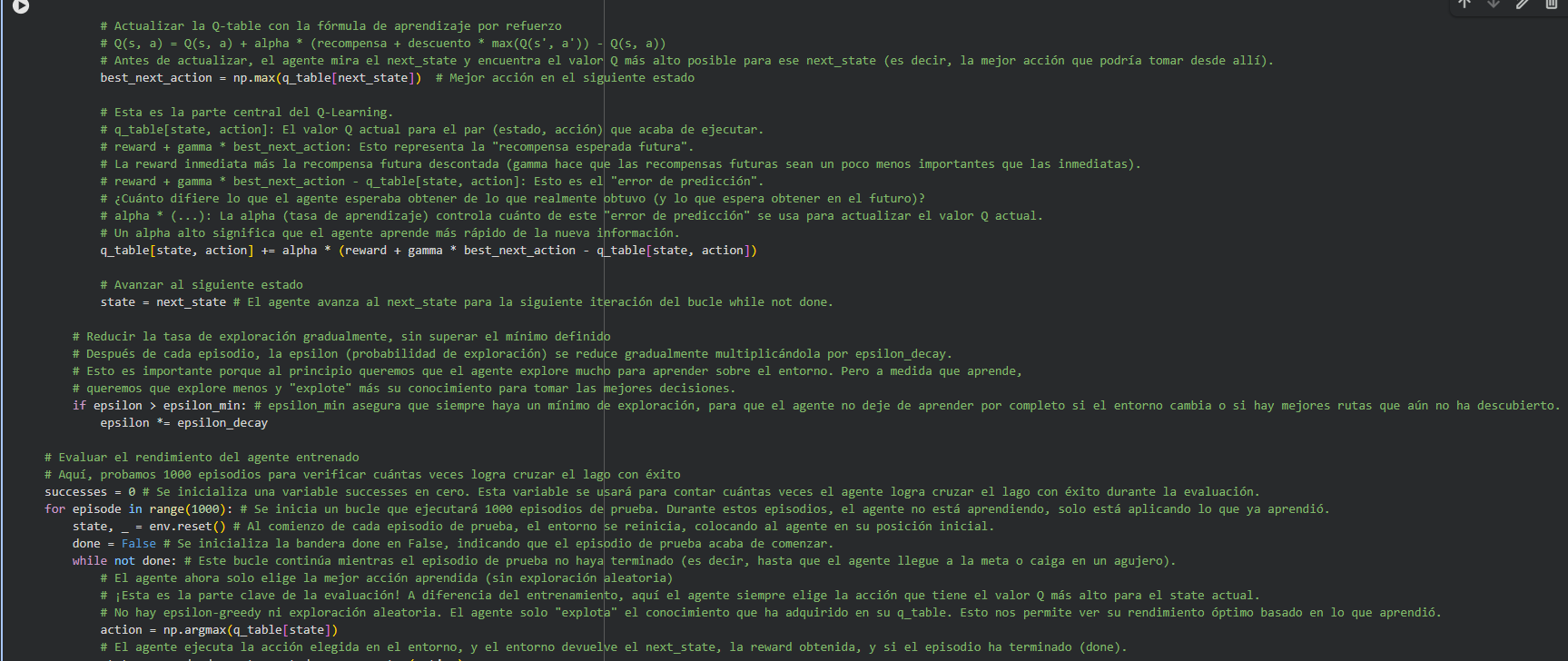
num_episodes = 30000 # Darle más episodios para aprender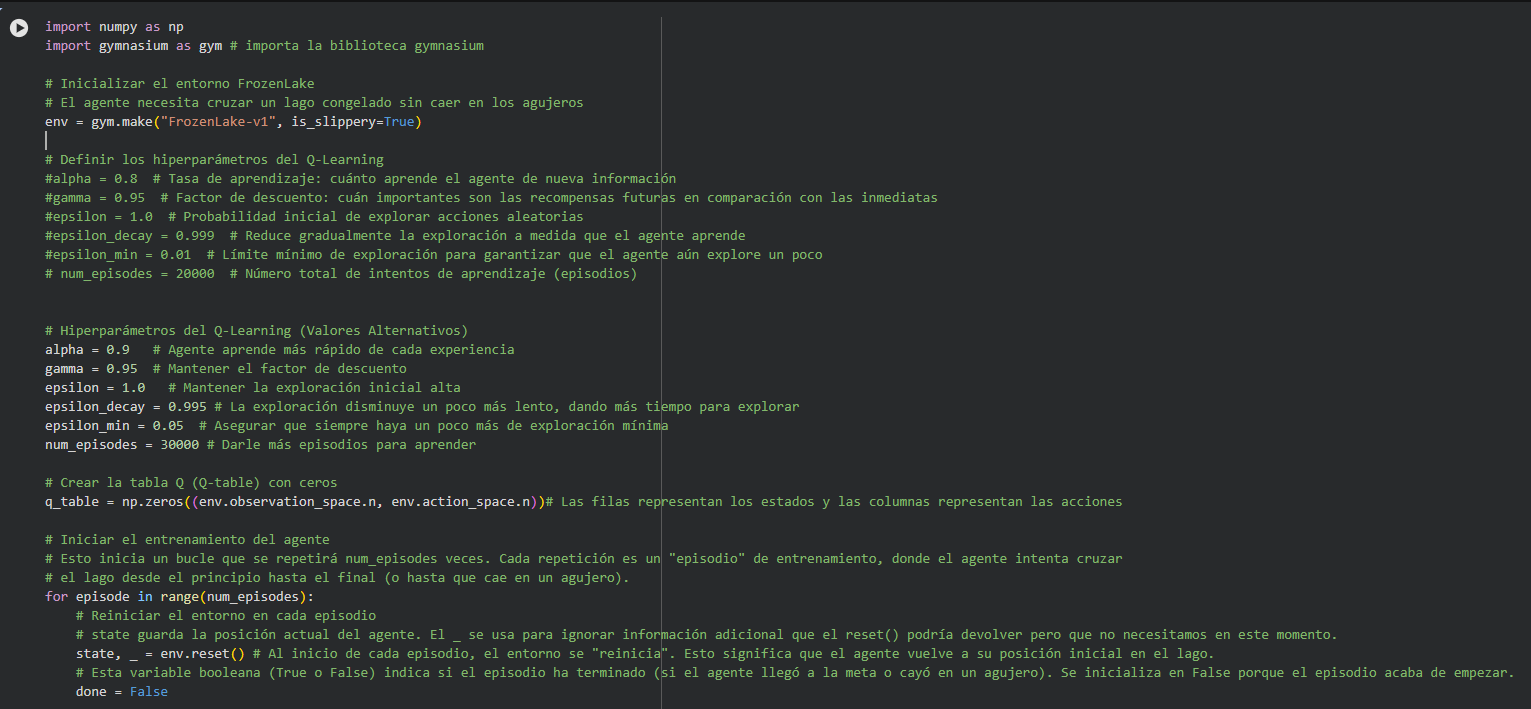
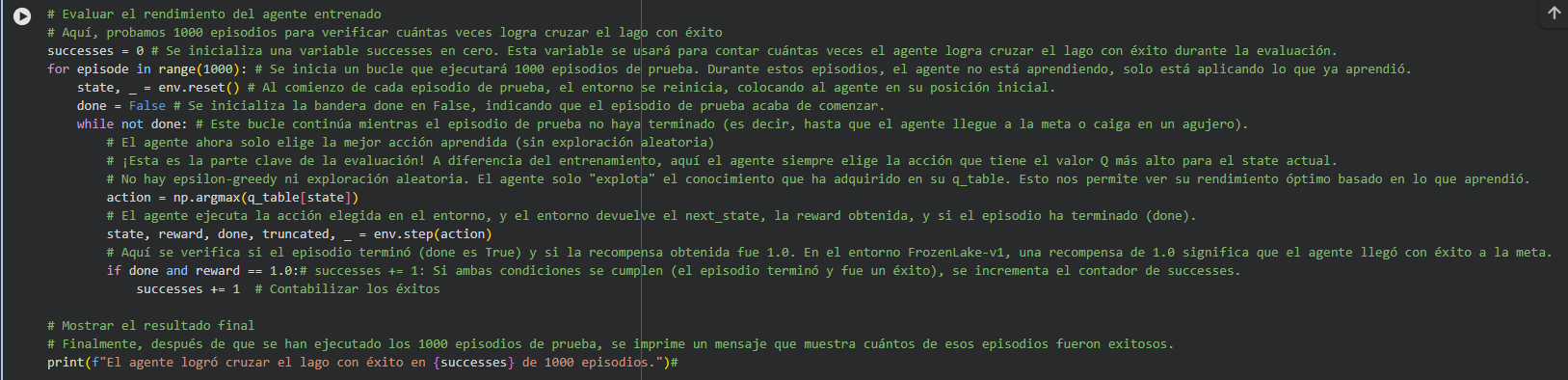
el resultado para los valores recomendados por Luri fue: El agente logró cruzar el lago con éxito en 110 de 1000 episodios.
el resultado para los valores aleatoreos elegidos fue: El agente logró cruzar el lago con éxito en 784 de 1000 episodios.

