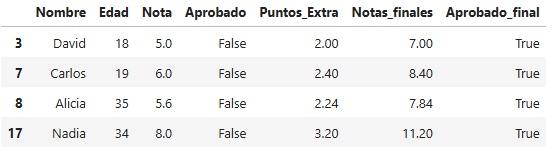
Se debe tener en cuenta que, al momento de realizar el último ítem, se debe cambiar el tipo Object de la columna Aprobado por el tipo bool. Sin embargo, no es tan simple como agregar .astype(bool), ya que esto modificará todos los valores a True. Por lo tanto, se debe utilizar .str.strip() para convertir los valores a tipo str (sin espacios), y luego utilizar la función map para convertirlos a valores booleanos.
Codigo
url = 'https://gist.githubusercontent.com/ahcamachod/807a2c1cf6c19108b2b701ea1791ab45/raw/fb84f8b2d8917a89de26679eccdbc8f9c1d2e933/alumnos.csv'
df_alumnos = pd.read_csv(url, delimiter=',')
#Reemplazamos los valores erroneos llamados Verdadero a True, ademas de reemplazar los NaN por 0
df_alumnos['Aprobado'] = df_alumnos['Aprobado'].replace('Verdadero', True)
df_alumnos = df_alumnos.fillna(0)
df_alumnos.head(5)
# Creamos la columna Puntos_Extra que sera un 40% del valor de la Nota del alumno
df_alumnos['Puntos_Extra'] = df_alumnos['Nota'] * 0.4
df_alumnos.tail(5)
# Creamos la columna Notas_finales sumando la Nota y los Puntos Extra
df_alumnos['Notas_finales'] = df_alumnos['Nota'] + df_alumnos['Puntos_Extra']
df_alumnos.sample(5)
# Creamos la columna Aprobado_final para saber si algun alumno aprobo con los puntos extra
df_alumnos['Aprobado_final'] = df_alumnos['Notas_finales'].apply( lambda x: True if x >= 7.0 else False)
#Comprobamos resultado
df_alumnos.sample(5)
# Revisamos los tipos de datos con los que trabajamos
df_alumnos.dtypes
# Se utiliza map ya que solo vamos a trabajar con una columna, si fueran mas, es mejor utilizar apply
df_alumnos['Aprobado'] = df_alumnos['Aprobado'].str.strip().map(lambda x: True if x == "True" else False)
df_alumnos
#Revisamos que se haya modificado el tipo Object a Bool
df_alumnos.dtypes
#Creamos el filtro
filtro = df_alumnos.apply(lambda x: x['Aprobado'] == False and x['Aprobado_final'] == True, axis=1)
filtro
#Aplicamos el filtro
filtrados = df_alumnos[filtro]
filtrados
Resultado ultimo item