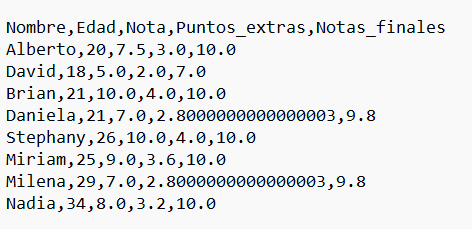
- Los estudiantes participaron en una actividad extracurricular y ganaron puntos extras. Estos puntos extras corresponden al 40% de su nota actual. Por lo tanto, crea una columna llamada "Puntos_extras" que contenga los puntos extras de cada estudiante, es decir, el 40% de su nota actual.
# Obtenemos el puntaje extra, que es el equivalente al 40% de la primera nota
df_alumnos['Puntos_extras'] = df_alumnos['Nota'].apply(lambda x: x*0.4)
df_alumnos
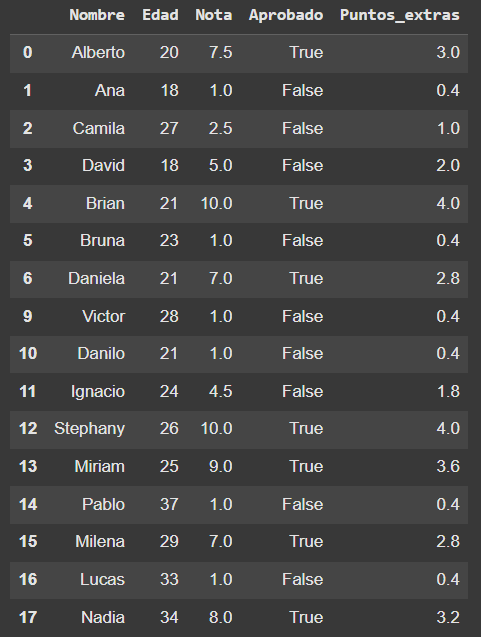
- Crea otra columna llamada "Notas_finales" que contenga las notas de cada estudiante sumadas con los puntos extras.
# .clip(upper=10) asegura que el valor no pase de 10.
df_alumnos['Notas_finales'] = (df_alumnos['Nota'] + df_alumnos['Puntos_extras']).clip(upper=10)
df_alumnos
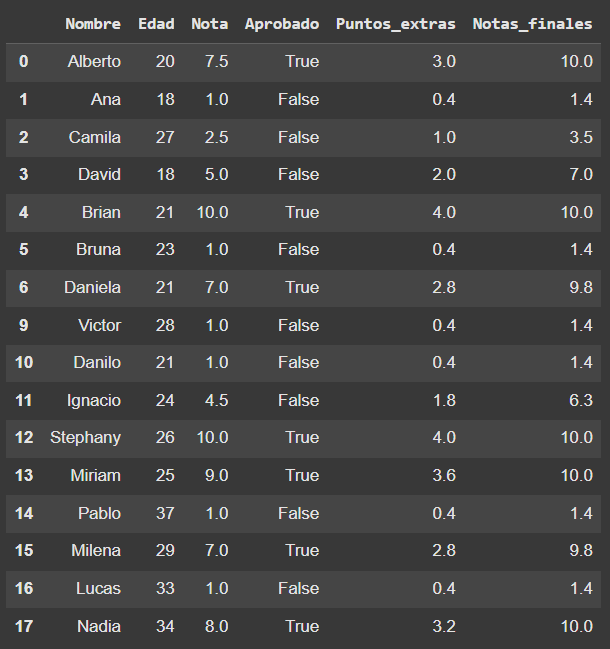
- Dado que hubo una puntuación extra, algunos estudiantes que no habían sido aprobados antes pueden haber sido aprobados ahora. En función de esto, crea una columna llamada "Aprobado_final" con los siguientes valores:
True: si el estudiante está aprobado (la nota final debe ser mayor o igual a 7.0).
False: si el estudiante está reprobado (la nota final debe ser menor que 7.0).
df_alumnos['Aprobados_final'] = df_alumnos['Notas_finales'].apply(lambda x: True if x >= 7 else False)
df_alumnos
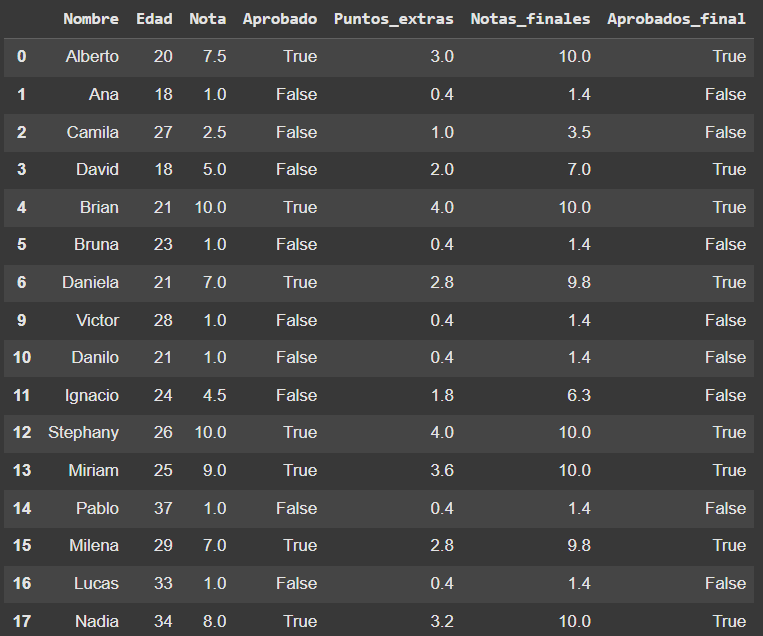
# Me muestra que alumno pasó de estar reprobado a aprobado
df_alumnos.query('Aprobado == "False" and Aprobados_final == True')

- Realiza una selección y verifica qué estudiantes no habían sido aprobados anteriormente, pero ahora fueron aprobados después de sumar los puntos extras.
# Creamos una condición booleana que identifica a los estudiantes aprobados según la columna 'Aprobados_final'
filtro_aprobados_final = df_alumnos['Aprobados_final'] == True
# Aplicamos el filtro y creamos una copia del DataFrame original con solo los estudiantes aprobados
df_alumnos_aprobados_final = df_alumnos[filtro_aprobados_final].copy()
df_alumnos_aprobados_final
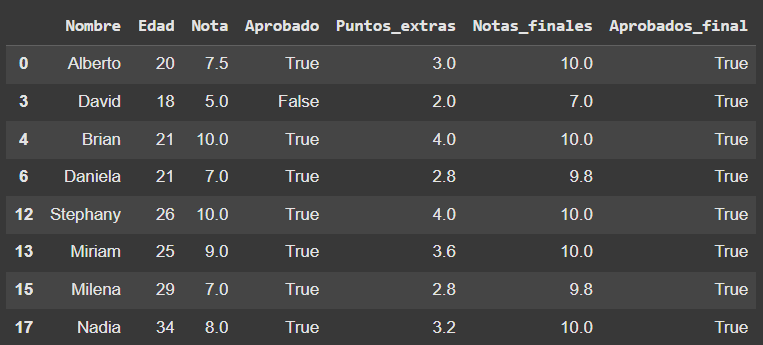
# Eliminamos las columnas 'Aprobado' y 'Aprobados_final' ya que no son necesarias para el análisis posterior
df_alumnos_aprobados_final.drop(['Aprobado','Aprobados_final'],axis=1,inplace=True)
df_alumnos_aprobados_final
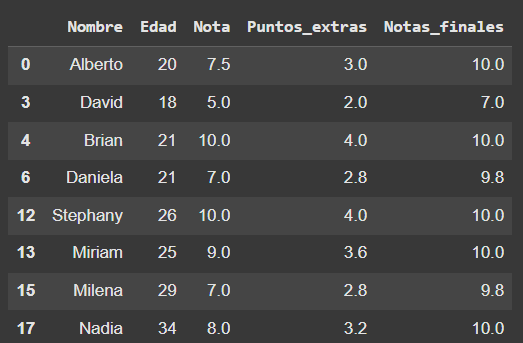
# Guardamos el DataFrame resultante en un archivo CSV sin incluir el índice
df_alumnos_aprobados_final.to_csv('/content/drive/MyDrive/Pandas/ejercicio_alumnos.csv',index=False)
# Leemos el archivo CSV para verificar que fue guardado correctamente
pd.read_csv('/content/drive/MyDrive/Pandas/ejercicio_alumnos.csv')
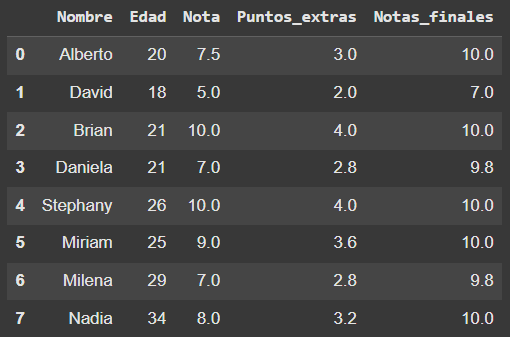
- Archivo resultante: