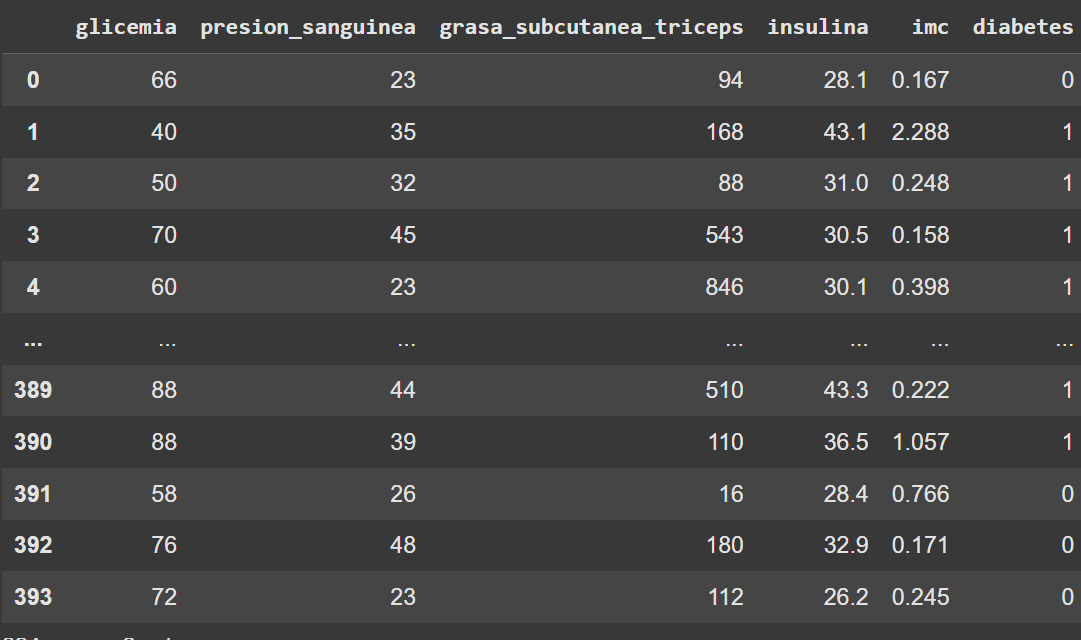
Lectura de datos y separación de variables explicativas y respuesta
import pandas as pd
url_desafio = 'https://raw.githubusercontent.com/DanielRaiicHu/clasificacion_validacion_y_metricas/main/diabetes.csv'
datos_desafio = pd.read_csv(url_desafio)
datos_desafio
X_desafio = datos_desafio.drop(columns='diabetes',axis=1)
y_desafio = datos_desafio['diabetes']
División de Datos: Entrenamiento, Validación y Prueba
from sklearn.model_selection import train_test_split
# División inicial: General vs Prueba
X_desafio, X_test_desafio, y_desafio, y_test_desafio = train_test_split(X_desafio, y_desafio, test_size= 0.05, stratify = y_desafio, random_state = 5)
# División secundaria: Entrenamiento vs Validación
X_train_desafio, X_val_desafio, y_train_desafio, y_val_desafio = train_test_split(X_desafio, y_desafio, stratify = y_desafio, random_state = 5)
Modelos: DecisionTreeClassifier y RandomForestClassifier
# Modelo Árbol
from sklearn.tree import DecisionTreeClassifier
modelo_arbol_desafio = DecisionTreeClassifier(max_depth=3, random_state= 5) # Límite de profundidad = 3
modelo_arbol_desafio.fit(X_train_desafio,y_train_desafio) # Vuelve a entrenar
print(f'La exactitud del Modelo de Árbol con el conjunto de entrenamiento es de: {modelo_arbol_desafio.score(X_train_desafio,y_train_desafio)}')
print(f'La exactitud del Modelo de Árbol con el conjunto de validación es de: {modelo_arbol_desafio.score(X_val_desafio,y_val_desafio)}')
# Respuesta:
# La exactitud del Modelo con de Árbol el conjunto de entrenamiento es de: 0.7571428571428571
# La exactitud del Modelo con de Árbol el conjunto de validación es de: 0.776595744680851
# Modelo Forest
from sklearn.ensemble import RandomForestClassifier
modelo_forest_desafio = RandomForestClassifier(max_depth=2, random_state= 5) # Límite de profundidad = 2
modelo_forest_desafio.fit(X_train_desafio,y_train_desafio) # Vuelve a entrenar
print(f'La exactitud del Modelo Forest con el conjunto de entrenamiento es de: {modelo_forest_desafio.score(X_train_desafio,y_train_desafio)}')
print(f'La exactitud del Modelo Forest con el conjunto de validación es de: {modelo_forest_desafio.score(X_val_desafio,y_val_desafio)}')
# Respuesta:
# La exactitud del Modelo Forest con el conjunto de entrenamiento es de: 0.7285714285714285
# La exactitud del Modelo Forest con el conjunto de validación es de: 0.7021276595744681
Matriz de Confusión
from sklearn.metrics import confusion_matrix
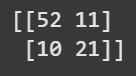
# Matriz de Confusión tipo Array - Modelo Árbol
y_previsto_arbol_desafio = modelo_arbol_desafio.predict(X_val_desafio)
matriz_confusion_arbol_desafio = confusion_matrix(y_val_desafio,y_previsto_arbol_desafio)
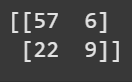
print(matriz_confusion_arbol_desafio)
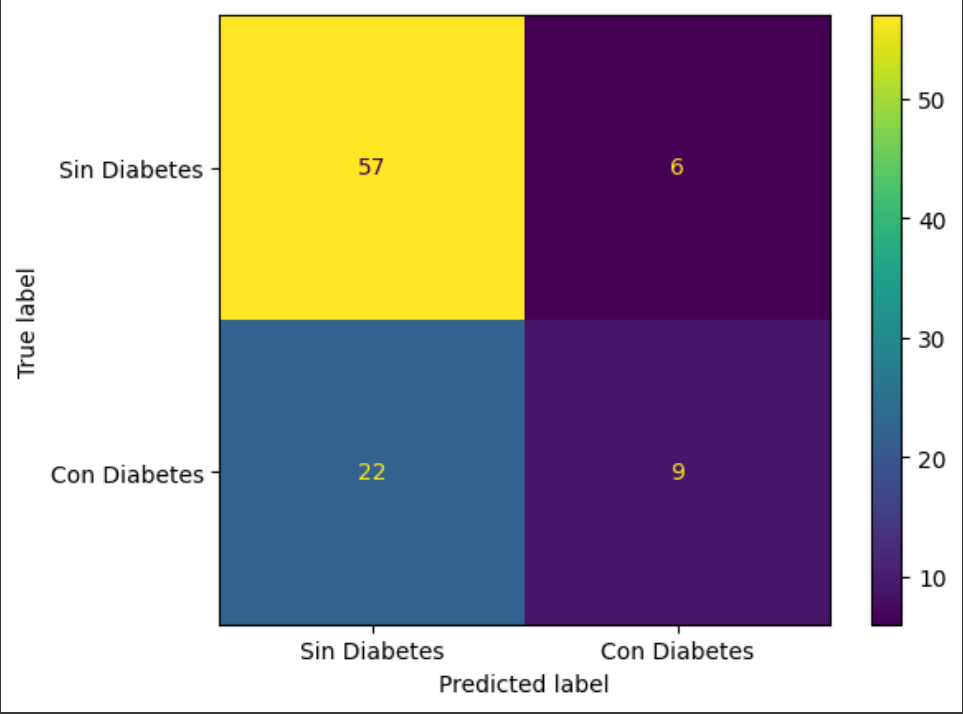
# Matriz de Confusión - Modelo Árbol
visualizacion_arbol_desafio = ConfusionMatrixDisplay(
confusion_matrix=matriz_confusion_arbol_desafio,
display_labels=['Sin Diabetes', 'Con Diabetes'] # Etiquetas para las clases 0 y 1
)
visualizacion_arbol_desafio.plot();
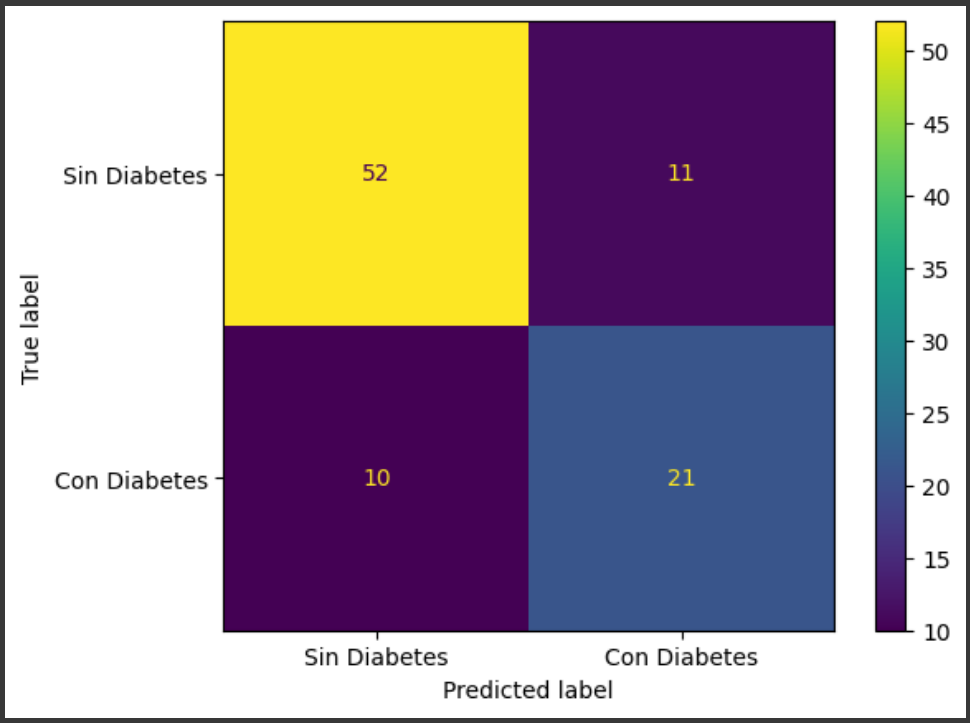
# Matriz de Confusión tipo Array - Modelo Forest
y_previsto_forest_desafio = modelo_forest_desafio.predict(X_val_desafio)
matriz_confusion_forest_desafio = confusion_matrix(y_val_desafio,y_previsto_forest_desafio)
print(matriz_confusion_forest_desafio)
# Matriz de Confusión - Modelo Forest
visualizacion_forest_desafio = ConfusionMatrixDisplay(
confusion_matrix=matriz_confusion_forest_desafio,
display_labels=['Sin Diabetes', 'Con Diabetes'] # Etiquetas para las clases 0 y 1
)
visualizacion_forest_desafio.plot();