
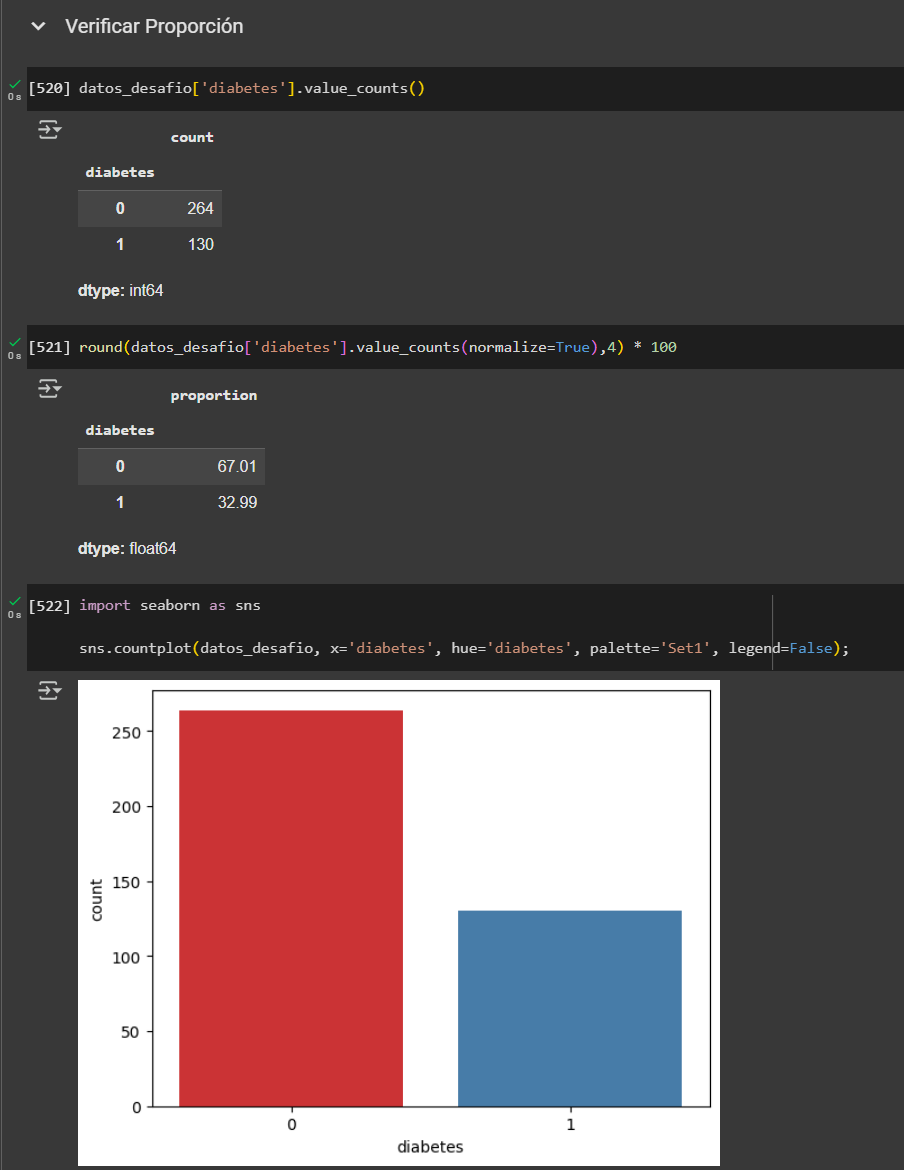
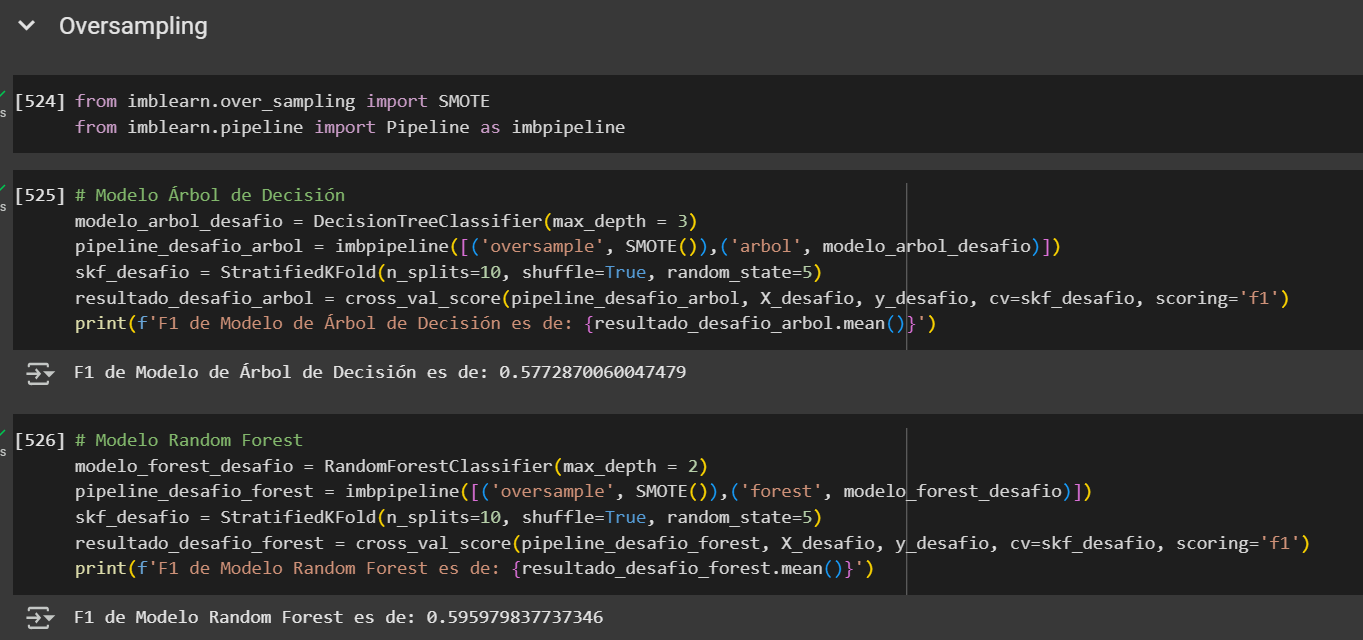
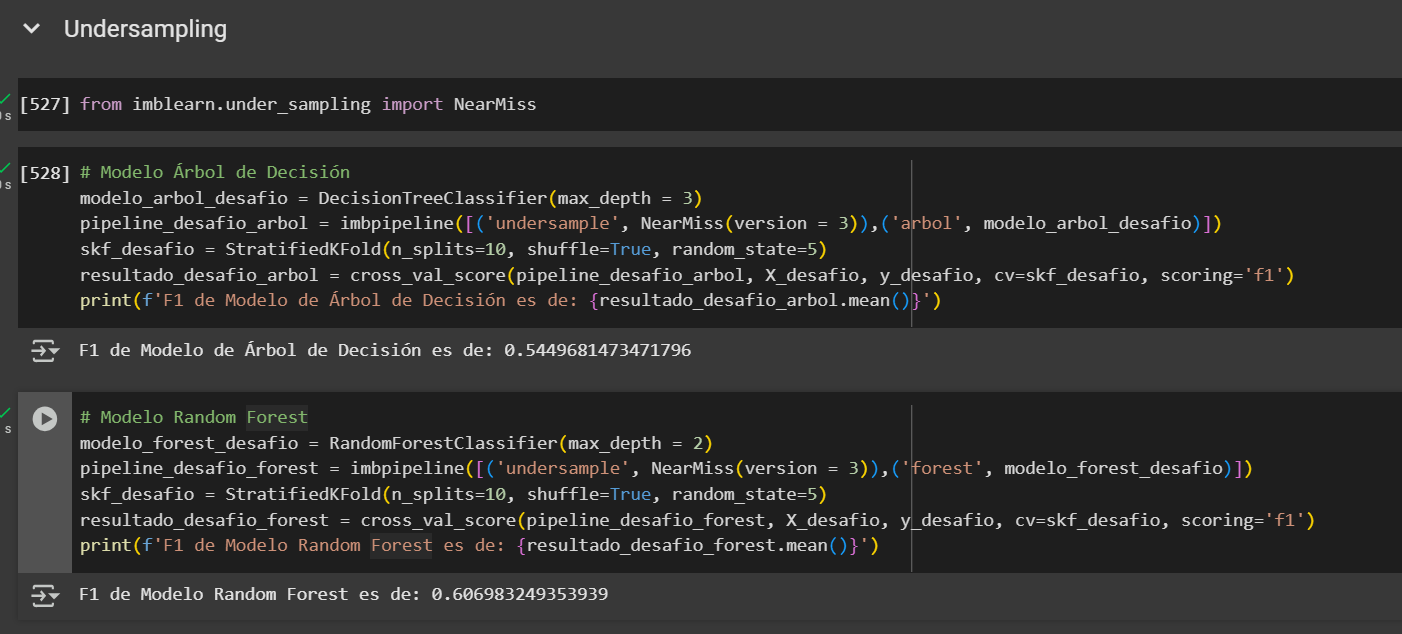
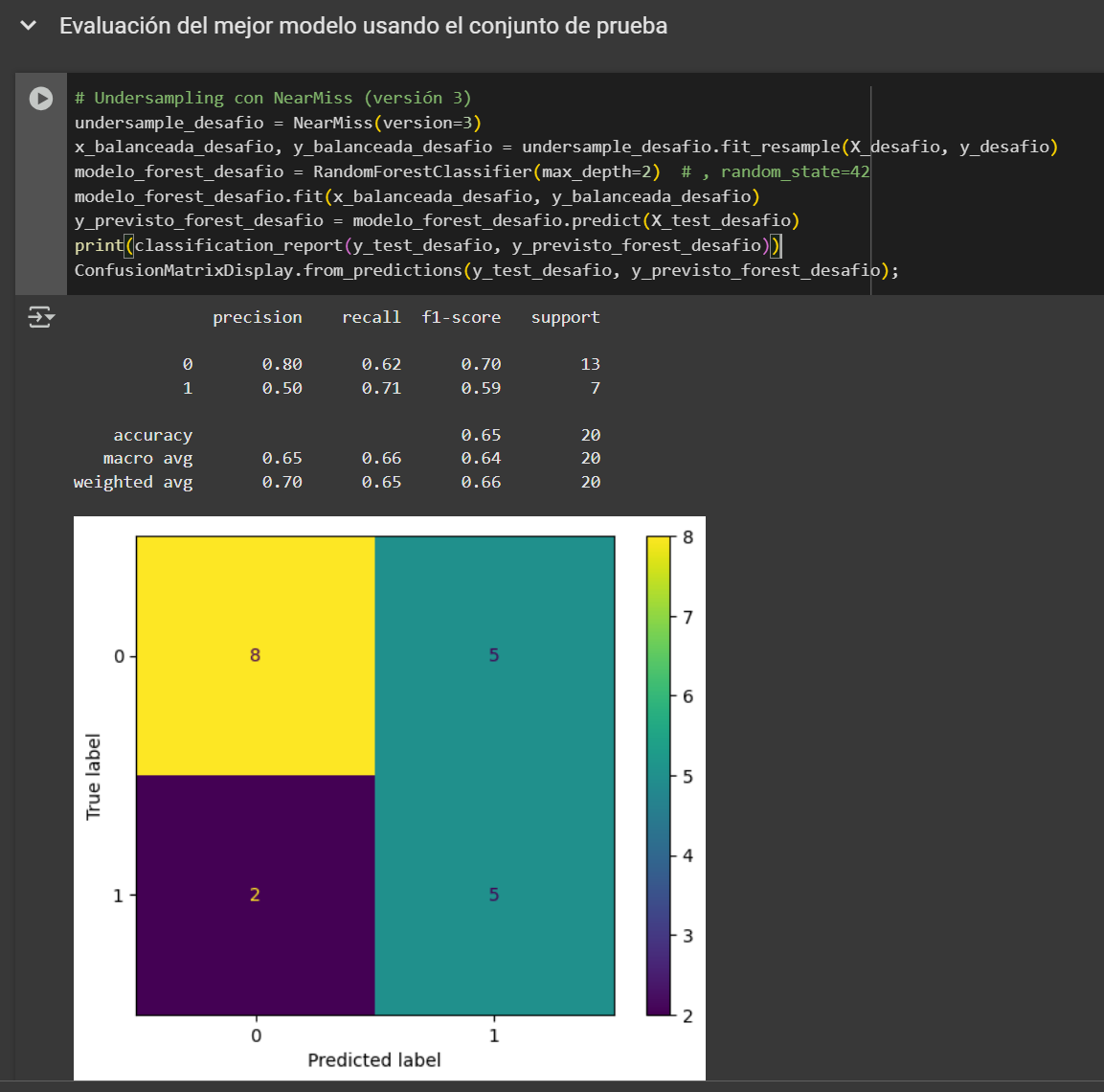
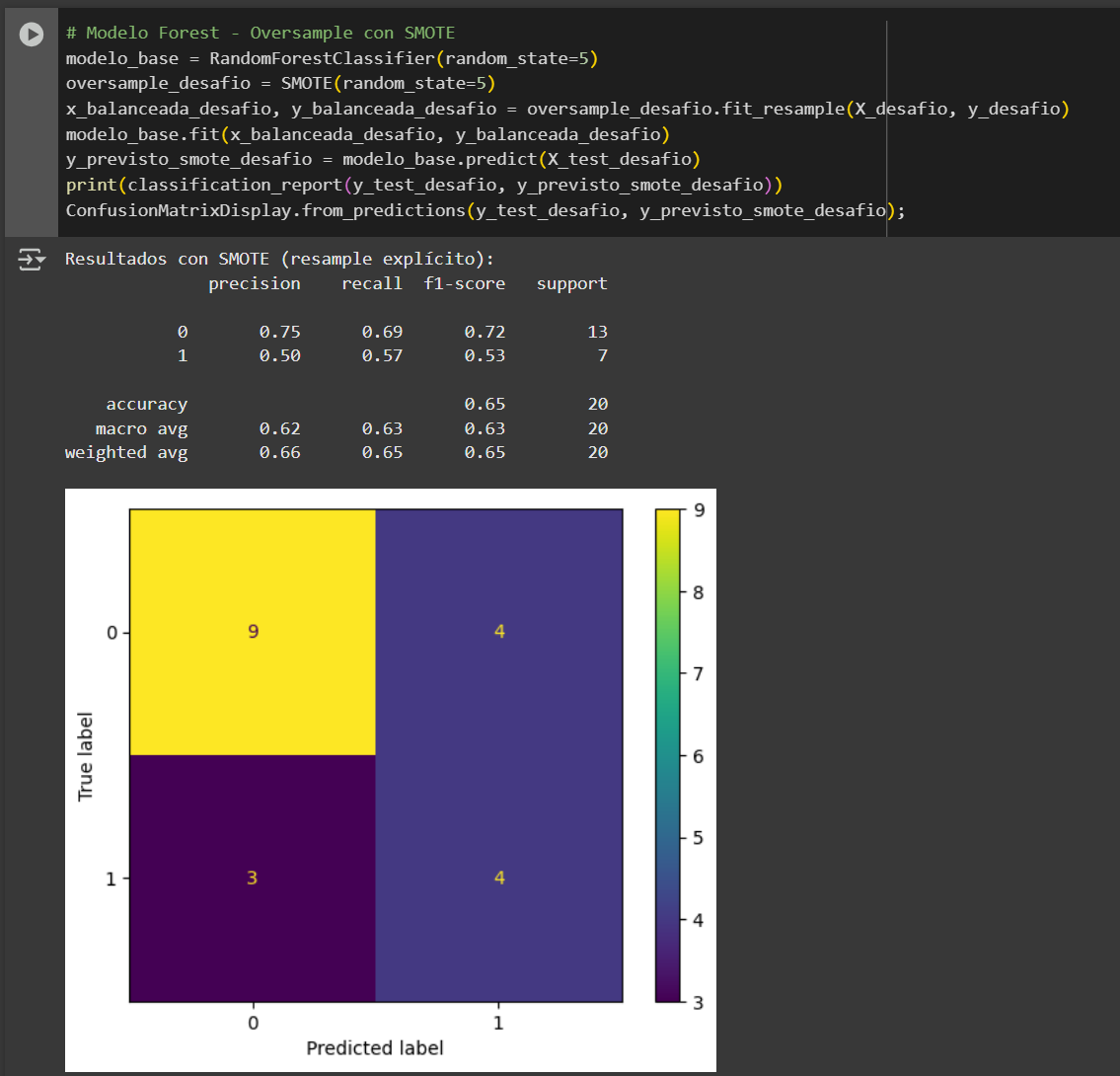
En este caso, el Modelo Random Forest con Undersample mediante NearMiss presenta mejor desempeño para nuestro objetivo, ya que logra mayor recall en la clase positiva y reduce la cantidad de falsos negativos, lo que es clave cuando no queremos dejar pasar casos relevantes sin detectar.


