Como reemplazo el codigo que adjunto su apoyo
Ingrese aquí la descripción de esta imagen para ayudar con la accesibilidad

Como reemplazo el codigo que adjunto su apoyo
Ingrese aquí la descripción de esta imagen para ayudar con la accesibilidad


Hola Jefferson, espero que estés bien
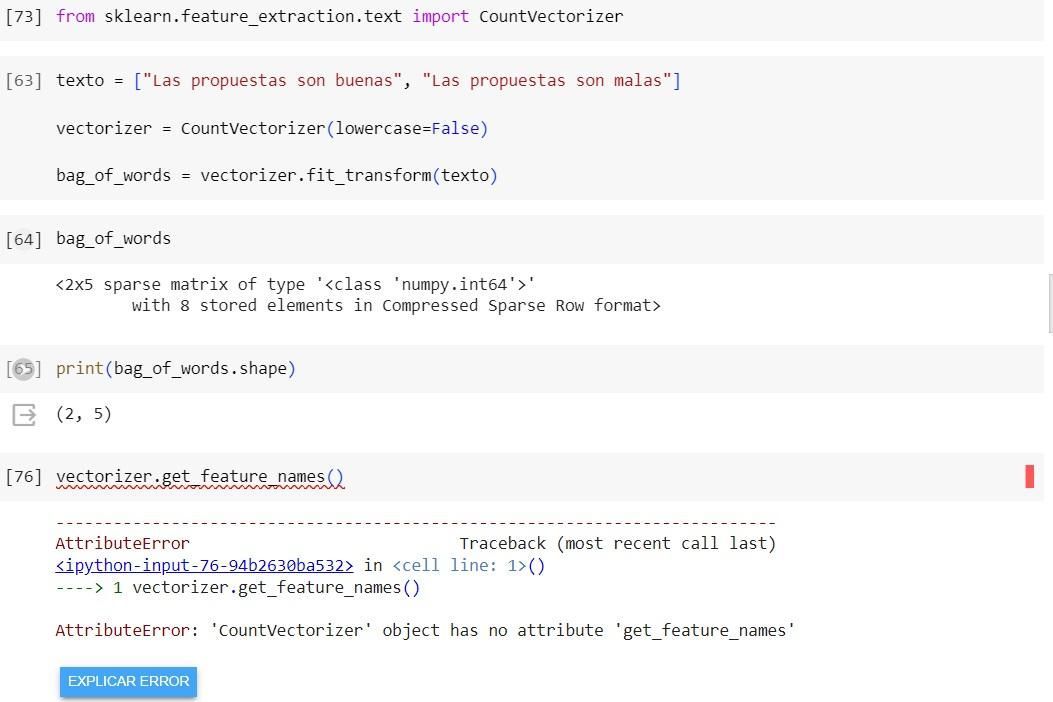
Si estás obteniendo un error que indica que get_feature_names no se encuentra en CountVectorizer(), puede ser debido a que estás intentando llamar a get_feature_names en un objeto de tipo CountVectorizer, que no tiene ese método directamente.
get_feature_names es un método que se encuentra en los objetos de tipo CountVectorizer después de que se ha ajustado (fit) el vectorizador a los datos. Este método se utiliza para obtener los nombres de las características que se han extraído del texto.
Aquí hay un ejemplo de cómo se puede utilizar get_feature_names después de ajustar un CountVectorizer a los datos:
from sklearn.feature_extraction.text import CountVectorizer
# Datos de ejemplo
corpus = ['Este es un ejemplo de texto', 'Otro ejemplo de texto']
# Inicializar y ajustar CountVectorizer
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
# Obtener los nombres de las características
feature_names = vectorizer.get_feature_names()
# Imprimir los nombres de las características
print(feature_names)
En este ejemplo, fit_transform se utiliza para ajustar el CountVectorizer a los datos y transformar el texto en una matriz de conteo de características. Luego, get_feature_names se utiliza para obtener los nombres de las características extraídas. Espero respuesta si el problema se ha solucionado.
Saludos y buenos estudios
{kind=link}