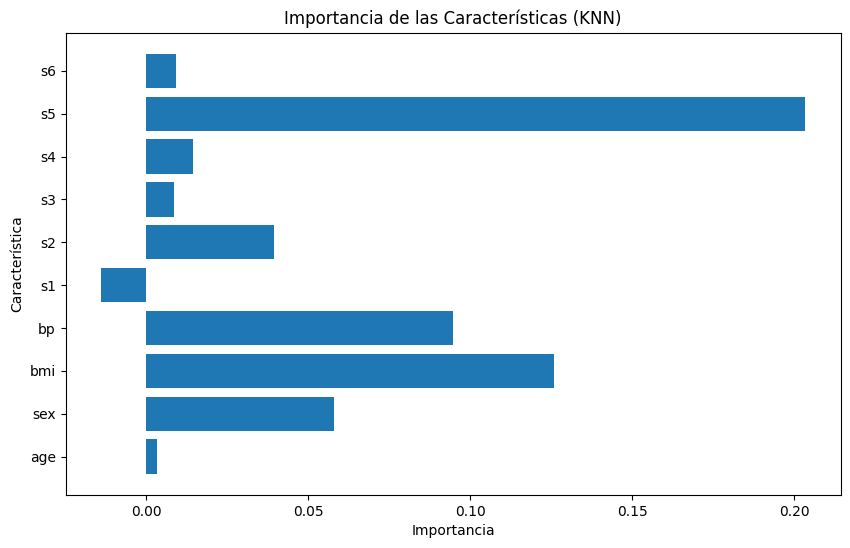
Para el desarrollo de este codigo nos basamos en los codigos anteriormente desarrollados y procedimos a solicitar ayuda a la IA para que nos explicara como podiamos Crear el modelo KNN con parámetros por defecto (k=5 vecinos) y lo entrenamos con los datos de entrenamiento. pues a diferencia de Random Forest, KNN no construye nada internamente — simplemente memoriza los datos para comparar después.
# Paso 1: importamos las librerias de trabajo
from sklearn.neighbors import KNeighborsRegressor
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
import numpy as np
# Cargar el dataset Diabetes
diabetes = load_diabetes()
# Convertir a DataFrame y separar atributos y etiquetas
X = diabetes.data
y = diabetes.target
# Normalizar los datos (importante para KNN)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Dividir en entrenamiento (80%) y prueba (20%)
X_train, X_test, y_train, y_test = train_test_split(
X_scaled, y, test_size=0.2, random_state=42
)
# Paso 2: Entrenar el modelocrear el modelo de trabajo
# Crea el modelo KNN con parámetros por defecto (k=5 vecinos) y lo entrena con los datos de entrenamiento. KNN no construye nada internamente — simplemente memoriza los datos para comparar después. Mientras que Random Forest si.
model = KNeighborsRegressor()
model.fit(X_train, y_train)
#Paso 3: Obtener la importancia de las características manualmente
# KNN no tiene feature_importances_, se calcula midiendo
# cálculo de cuánto sube el error al eliminar cada característica
importances = [] # Crea una lista vacía donde se guardarán las importancias. model.score()
base_score = model.score(X_test, y_test) # calcula el R² base del modelo usando todas las características — es el punto de referencia para medir cuánto aporta cada variable. En resumen R² es la base con todas las características
for i in range(X_test.shape[1]): # Recorre cada columna (característica) de los datos de prueba. X_test.shape[1] devuelve el número total de columnas.
X_test_permutado = X_test.copy() # Hace una copia exacta de los datos de prueba para no modificar los datos originales en cada iteración del ciclo.
X_test_permutado[:, i] = np.random.permutation(X_test_permutado[:, i]) # Desordena la columna i # Desordena aleatoriamente los valores de la columna i. Esto destruye la relación entre esa característica y el resultado, simulando que esa variable no existe o no aporta información útil.
score_sin_feature = model.score(X_test_permutado, y_test) # Mide el R² del modelo sin esa característica (desordenada). Si el score baja mucho respecto al base, significa que esa variable era importante.
importances.append(base_score - score_sin_feature) # Calcula la importancia de la característica como la diferencia entre el score base y el score sin ella. Valor alto = la variable importa mucho; valor cercano a 0 = casi no influye.
importances = np.array(importances) # Convierte la lista de importancias a un arreglo numpy para que matplotlib pueda graficarlo.
feature_names = diabetes.feature_names # feature_names obtiene los nombres de las columnas del dataset para usar como etiquetas.
# Paso 4: Crear un gráfico de barras
#Crea el gráfico: un lienzo de 10×6 pulgadas, barras horizontales donde cada barra representa una característica y su longitud indica su importancia, con título, etiquetas de ejes y finalmente lo muestra en pantalla.
plt.figure(figsize=(10, 6))
plt.barh(feature_names, importances)
plt.title("Importancia de las Características (KNN)")
plt.xlabel("Importancia")
plt.ylabel("Característica")
plt.show()